3D sound localization
'3D sound localization' refers to the acoustical engineering technology that is being used to identify the location of a sound source in a three-dimensional space. Usually the location of the source is determined by the direction of the coming sound waves (horizontal and vertical angles) and the distance between the source and the sensors. We note that the sound source localization problem is also a source localization problem. It involves the structure arrangement design of the sensors and signal processing techniques.
Humans and most mammals use binaural hearing to process the sound localization with two ears, so it is difficult to localize using monaural hearing especially in 3D space. For example, when you hear a sound, you need to determine which direction was the sound sent from and what message it contained, based on binaural hearing, compared information received from each of the two ears. The whole procedure is extremely complex and involves a lot of synthesis.
Motivation
The interest in sound localization is widely increasing due to the need for improved solutions in some audio and acoustics fields, such as hearing aids, surveillance[1] and navigation. Existing real-time passive sound localization systems are mainly based on the time-difference-of-arrival (TDOA) approach, but this limits sound localization to two-dimensional space. The most important problem is that systems cannot be used realistically with noisy conditions and 3D implementation.
Applications
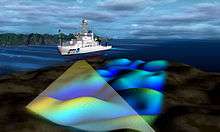
There are many applications of sound source localization such as sound source separation, sound source tracking and speech enhancement. Underwater sonar uses sound source localization techniques to identify the location of a target. It is also used in robots for effective human-robot interaction. With the increasing demand of robotic hearing, some applications such as human-machine interface, handicappers' aid and some military applications are being widely exploited.
Cues for sound localization
Localization cues[2] are the features the can help us localize sound. Cues for the sound localization include the binaural cues and monoaural cues.
- Monoaural cues can be obtained by means of spectral analysis. Monoaural cues are generally used in vertical localization
- Binaural cues are generated by the difference of hearing between the left and right ears. These include interaural time difference(ITD) and interaural intensity difference(ILD). Binaural cues are mostly used for the horizontal localization.
Methods
There are many 3D sound localization methods that are used for various applications.
- Different types of sensor structure can be used such as microphone array and binaural hearing robot head.[3]
- Different techniques can be used to get the optimal results, such as neural network, maximum likelihood and Multiple signal classification (MUSIC).
- According to the timeliness, there are real-time methods and off-line methods
• Microphone Array Approach
Steered Beamformer Approach
This approach uses eight microphones and combined with a steered beamformer which enhanced by the Reliability Weighted Phase Transform (RWPHAT), and the results finally filtered by a particle filter that tracks each source and also prevents false directions. The motivation of using this method is that based on previous research, the sound tracking and localization only applied for a single sound source, but this method is used for multiple sound sources tracking and localizing.
Beamformer-based Sound Localization
To maximum the output energy of a delay-and-sum beamformer in order to find the maximum value of the output of a beamformer which is steered in all possible directions. Using the Reliability Weighted Phase Transform (RWPHAT) method, The output energy of M-microphone delay-and-sum beamformer is

Where E indicates the energy, and K is a constant, is the microphone pairs cross-correlation defined by Reliability Weighted Phase Transform:


the weighted factor reflect the reliability of each frequency component, and defined as the Wiener Filter gain , where is an estimate of a prior SNR at microphone, at time frame , for frequency , computed using the decision-directed approach.[4]






The is the signal from microphone and is the delay of arrival for that microphone. And the more specific procedure of this method is proposed by Valin and Michaud[5]



The advantage of this method is it not only can detect the sound direction, but also can derive the distance of sound sources. But the main drawback of this beamforming approach is the accuracy and capability of sound localization are not that perfect as neural network approach using on the moving speakers.
Collocated Microphone Array Approach
Real-time sound localization uses a collocated array named Acoustic Vector Sensor (AVS) array.[6]
Acoustic Vector Array
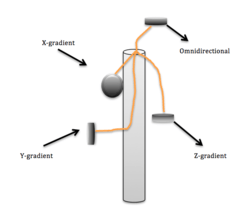
• AVS Contains 3 orthogonally installed acoustic particle velocity gradient microphones which are X, Y and Z array shown, and one omnidirectional acoustic microphone O.
• This type of array has been widely used under water.
• AVS uses the Offline Calibration Process[7] to measure and interpolate the impulse response of X, Y, Z and O arrays, to obtain their steering vector.
A sound signal is first windowed using a rectangular window, then each resulting segment signal is created as a frame. 4 parallel frames are detected from XYZO array and used for DOA estimation. The 4 frames are split into small blocks with equal size, then the Hamming window and FFT are used to convert each block from a time domain to a frequency domain. Then the output of this system is represented by a horizontal angle and a vertical angle of the sound sources which is found by the peak in the combined 3D spatial spectrum.
The advantages of this array, compared with past microphone array, are that this device has a high performance even if the aperture is small, and it can localize multiple low frequency and high frequency wide band sound sources simultaneously. Applying an O array can make more available acoustic information, such as amplitude and time difference. Most importantly, XYZO array has a better performance with a tiny size.
The AVS is one kind of collocated multiple microphone array, it make use of a multiple microphone array approach for estimating the sound directions by multiple arrays and then finds the locations by using reflection informations such as where the direction is detected where different arrays cross.
Motivation of the Advanced Microphone array
Sound reflections always occur in an actual environment and microphone arrays[8] cannot avoid observing those reflections. This multiple array approach was tested using fixed arrays in the ceiling; the performance of the moving scenario still need to be tested.
*Learning how to apply Multiple Microphone Array
Angle uncertainty (AU) will occur when estimating direction, and position uncertainty (PU) will also aggravate with increasing distance between the array and the source. We know that:

where r is the distance between array center to source, and AU is angle uncertainly. Measurement is used for judging whether two directions cross at some location or not. Minimum distance between two lines:

whereand are two directions, are vectors parallel to detected direction, and are the position of arrays.




If

two lines are judged as crossing. When two lines are crossing, we can compute the sound source location using the following:

is the estimation of sound source position, is the position where each direction intersect the line with minimum distance, and is the weighted factors. As the weighting factor , we determined use or from the array to the line with minimum distance.





• Binaural Hearing Approach
Learning method for binaural hearing
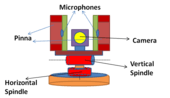
Binaural hearing Learning[3] is a bionic method. The sensor is a robot dummy head with 2 sensor microphones along with the artificial pinna(reflector). The robot head has 2 rotation axes and can rotate horizontally and vertically. The reflector causes the spectrum change into a certain pattern for incoming white noise sound wave and this pattern is used for the cue of the vertical localization. Cue used for horizontal localization is ITD.
The system should make use of a learning process using neural networks by rotating the head with a settled white noise sound source and analyzing the spectrum. Experiments show that the system can identify the direction of the source well in a certain range of angle of arrival. But it cannot identify the sound coming outside the range due to the collapsed spectrum pattern of the reflector.
Binaural hearing use only 2 microphones and is capable of concentrating on one source amaong noises and different sources.
Head-related Transfer Function (HRTF)
In the real sound localization, the whole head and the torso have an important functional role, not only the two pinnae. This function can be described as spatial linear filtering and the filtering is always quantified in terms of Head-Related Transfer Function (HRTF).[9]
HRTF also uses the robot head sensor, which is the binaural hearing model. This model has multiple inputs. The HRTF can be derived based on various cues for localization. Sound localization with HRTF is flitering the input signal with a filter which is designed based on the HRTF. Instead of using the neural networks, a head-related transfer function is used and the localization is based on a simple correlation approach.
See more: Head-related transfer function.
Cross-power spectrum phase (CSP) analysis
CSP method[10] is also used for the binaural model. The idea is that the angle of arrival can be derived through the time delay of arrival (TDOA) between two microphones, and TDOA can be estimated by finding the maximum coefficients of CSP. CSP coefficients are derived by:
![{\displaystyle csp_{ij}(k)={\text{IFFT}}\left\{{\frac {{\text{FFT}}[s_{i}(n)]\cdot {\text{FFT}}[s_{j}(n)]^{*}}{\left|{\text{FFT}}[s_{i}(n)]\right\vert \cdot \left|{\text{FFT}}[s_{j}(n)]\right\vert \quad }}\right\}\quad }](../I/m/7edeb234c5d51c97f20561585f8b3d5c55149f50.svg)
Where and are signals entering the microphone and respectively
Time delay of arrival() then can be estimated by:






Sound source direction is

Where is the sound propagation speed, is the sampling frequency and is the distance with maximum time delay between 2 microphones.



CPS method does not require the system impulse response data that HRTF needs. An expectation-maximization algorithm is also used for localizing several sound sources and reduce the localization errors. The system is capable of identifying several moving sound source using only two microphones.
2D sensor line array
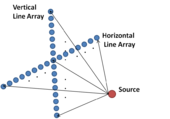
In order to estimate the location of a source in 3d space, we can use 2 line sensor arrays by respectively putting them horizontally and vertically.
An example is a 2D line array used for underwater source localization.[11] By processing the data from 2 arrays using the maximum likelihood method, the direction, range and depth of the source can be identified simultaneously.
Unlike the binaural hearing model, this method is much more like a spectral analysis method. The method can be used for localizing a source which is far away, but the system could be much more expensive than the binaural model because it needs more sensors and power.
Hierarchical Fuzzy Artificial Neural Networks Approach
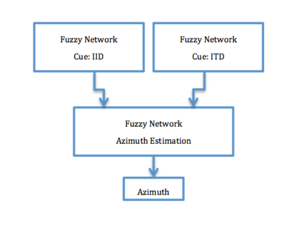
This sound localization system was inspired by biologically binaural sound localization. It is still not understood how animals with two ears and pea-sized brains such as some primitive mammals, are able to perceive 3D space and process sounds. Some animals experience difficulty in 3D sound location, due to the small heads and the wavelength of communication sound may be much larger than their head diameter, as is the case with frogs.
Based on previous binaural sound localization methods, a hierarchical fuzzy artificial neural network system combines interaural time difference(ITD-based) and interaural intensity difference(IID-based) sound localization methods for higher accuracy that is similar to that of humans. Hierarchical Fuzzy Artificial Neural Networks[12] were used with the goal of the same sound localization accuracy as human ears.
IID-based or ITD-based sound localization methods have a main problem called Front-back confusion.[13] In this sound localization based on a hierarchical neural network system, to solve this issue, an IID estimation is with ITD estimation. This system was used for broadband sounds and be deployed for non-stationary scenarios.
3D sound localization for monaural sound source
Typically, sound localization is performed by using two (or more) microphones. By using the difference of arrival times of a sound at the two microphones, one can mathematically estimate the direction of the sound source. However, the accuracy with which an array of microphones can localize a sound (using Interaural time difference) is fundamentally limited by the physical size of the array. If the array is too small, then the microphones are spaced too closely together so that they all record essentially the same sound (with ITF near zero), making it extremely difficult to estimate the orientation. Thus, it is not uncommon for microphone arrays to range from tens of centimeters in length (for desktop applications) to many tens of meters in length (for underwater localization). However, microphone arrays of this size then become impractical to use on small robots. even for large robots, such microphone arrays can be cumbersome to mount and to maneuver. In contrast, the ability to localize sound using a single microphone (which can be made extremely small) holds the potential of significantly more compact, as well as lower cost and power, devices for localization.
• conventional HRTF approach
A general way to implement 3d sound localization is to use the HRTF(Head-related transfer function). First, compute HRTFs for the 3D sound localization, which can be obtained by formulating two equations. One represents the signal of a given sound source and the other indicates the signal output from the dummy head microphones for the sound transferred from the source. Then, monaural input data are processed by these HRTFs, and the results are superposed to output from stereo-headphones.
It's a general way. But the disadvantage is that, a great amount of parametric operations are necessary for the whole set of filters to realize the 3D sound localization, which results in high computational complexity.
• DSP implementation of 3D sound localization
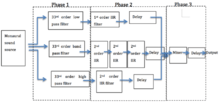
A DSP-based implementation of a realtime 3D sound localization approach with the use of an embedded DSP can reduce the computational complexity As shown in the figure, the implementation procedure of this realtime algorithm is divided into three phases, (i) Frequency Division, (ii) Sound Localization, and (iii) Mixing. In the case of 3D sound localization for a monaural sound source, the audio input data are divided into two: left and right channels and the audio input data in time series are processed one after another.[14]
A distinctive feature of this approach is that the audible frequency band is divided into three so that a distinct procedure of 3D sound localization can be exploited for each of the three subbands.
• single microphone approach
Consider the problem of estimating the incident angle of a sound, using only a single microphone. Such monaural localization is made possible by the structure of the pinna (outer ear), which modifies sound in a way that is dependent on its incident angle. A machine learning approach is adapted for monaural localization, using only a single microphone and an “artificial pinna” (that distorts sound in a direction-dependent way). The approach models the typical distribution of natural and artificial sounds, as well as the direction-dependent changes to sounds induced by the pinna.[15]
The experimental results also show that the algorithm is able to fairly accurately localize a wide range of sounds, such as human speech, dog barking, waterfall, thunder, and so on. In contrast to microphone arrays, this approach also offers the potential of significantly more compact, as well as lower cost and power, devices for sound localization.
See also
- 3D sound reconstruction
- Acoustic source localization
- Binaural recording
- Head-related transfer function
- Sound localization
- Vertical sound localization
References
- ↑ Keyrouz, Fakheredine; Diepold, Klaus; Keyrouz, Shady (September 2007). "High performance 3D sound localization for surveillance applications". 2007 IEEE Conference on Advanced Video and Signal Based Surveillance, AVSS 2007: 563–6. doi:10.1109/AVSS.2007.4425372.
- ↑ Goldstein, E.Bruce. Sensation and Perception(Eighth Edition). Cengage Learning. pp. 293–297. ISBN 978-0-495-60149-4.
- 1 2 Nakasima,H.; Mukai,T. (Oct 2005). 3D Sound Source Localization System Based on Learning of Binaural Hearing. Systems,Man and Cybernetics,IEEE 2005. 4. pp. 3534–3539. doi:10.1109/ICSMC.2005.1571695.
- ↑ Ephraim, Y.; Malah, D. (Dec 1984). "Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator". Acoustics, Speech and Signal Processing. 32 (6): 1109–21. doi:10.1109/TASSP.1984.1164453. ISSN 0096-3518.
- ↑ Valin, J.M.; Michaud, F.; Rouat, Jean (14–19 May 2006). "Robust 3D Localization and Tracking of Sound Sources Using Beamforming and Particle Filtering". Acoustics, Speech and Signal Processing. 4: IV. doi:10.1109/ICASSP.2006.1661100. ISSN 1520-6149.
- ↑ Liang, Yun; Cui, Zheng; Zhao, Shengkui; Rupnow, Kyle; Zhang, Yihao; Jones, Douglas L.; Chen, Deming (2012). "Real-time implementation and performance optimization of 3D sound localization on GPUs". Automation and Test in Europe Conference and Exhibition: 832–5. ISSN 1530-1591.
- ↑ Salas Natera, M.A.; Martinez Rodriguez-Osorio, R.; de Haro Ariet, L.; Sierra Perez, M. (2012). "Calibration Proposal for New Antenna Array Architectures and Technologies for Space Communications". IEEE Antennas and Wireless Propagation Letters. 11: 1129–32. doi:10.1109/LAWP.2012.2215952. ISSN 1536-1225.
- ↑ Ishi, C.T.; Even, J.; Hagita, N. (November 2013). "Using multiple microphone arrays and reflections for 3D localization of sound sources". 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2013): 3937–42. doi:10.1109/IROS.2013.6696919.
- ↑ Keyouz,F.; Diepold,K. (Aug 2006). An Enhanced Binaural 3D Sound Localization Algorithm. Signal Processing and Information Technology,IEEE 2006. pp. 662–665. doi:10.1109/ISSPIT.2006.270883.
- ↑ Hyun-Don Kim; Komatani, K.; Ogata, T.; Okuno,H.G. (Jan 2008). Evaluation of Two-Channel-Based Sound Source Localization using 3D Moving Sound Creation Tool. ICERI 2008. doi:10.1109/ICKS.2008.25.
- ↑ Tabrikian,J.; Messer,H. (Jan 1996). "Three-Dimensional Source Localization in a Waveguide". IEEE Transaction on Signal Processing. 44 (1): 1–13. doi:10.1109/78.482007.
- ↑ Keyrouz, Fakheredine; Diepold, Klaus (May 2008). "A novel biologically inspired neural network solution for robotic 3D sound source sensing". Soft Computing. Germany. 12 (7): 721–9. doi:10.1007/s00500-007-0249-9. ISSN 1432-7643.
- ↑ Hill, P.A.; Nelson, P.A.; Kirkeby, O.; Hamada, H. (December 2000). "Resolution of front-back confusion in virtual acoustic imaging systems". Journal of the Acoustical Society of America. 108 (6): 2901–10. doi:10.1121/1.1323235. ISSN 0001-4966.
- ↑ Noriaki, Sakamoto; wataru, Kobayashi; Takao, Onoye; Isao, Shirakawa (2001). "DSP implementation of 3D sound localization algorithm for monaural sound source". The 8th IEEE International Conference on Electronics, Circuits and Systems, 2001. ICECS 2001. 2: 1061–1064. ISBN 0-7803-7057-0.
- ↑ Saxena, Ashutosh; Y. Ng, Andrew (2009). "Learning Sound Location from a Single Microphone". IEEE International Conference onRobotics and Automation, 2009. ICRA '09. ISSN 1050-4729.