Communication-avoiding algorithms
Communication-Avoiding Algorithms minimize movement of data within a memory hierarchy for improving its running-time and energy consumption. These minimize the total of two costs (in terms of time and energy): arithmetic and communication. Communication, in this context refers to moving data, either between levels of memory or between multiple processors over a network. It is much more expensive than arithmetic.[1]
Motivation
Consider the following running-time model:[2]
- Measure of computation = Time per FLOP = γ
- Measure of communication = No. of words of data moved = β
⇒ Total running time = γ*(no. of FLOPs) + β*(no. of words)
From the fact that β >> γ as measured in time and energy, communication cost dominates computation cost. Technological trends[3] indicate that the relative cost of communication is increasing on a variety of platforms, from cloud computing to supercomputers to mobile devices. The report also predicts that gap between DRAM access time and FLOPs will increase 100x over coming decade to balance power usage between processors and DRAM.[1]
| FLOP rate (γ) | DRAM Bandwidth (β) | Network Bandwidth (β) |
|---|---|---|
| 59% / year | 23% / year | 26% / year |

Energy consumption increases by orders of magnitude as we go higher in the memory hierarchy.[4] United States president Barack Obama cited Communication-Avoiding Algorithms in the FY 2012 Department of Energy budget request to Congress:[1] “New Algorithm Improves Performance and Accuracy on Extreme-Scale Computing Systems. On modern computer architectures, communication between processors takes longer than the performance of a floating point arithmetic operation by a given processor. ASCR researchers have developed a new method, derived from commonly used linear algebra methods, to minimize communications between processors and the memory hierarchy, by reformulating the communication patterns specified within the algorithm. This method has been implemented in the TRILINOS framework, a highly-regarded suite of software, which provides functionality for researchers around the world to solve large scale, complex multi-physics problems.”
Objective
Communication-Avoiding algorithms are designed with the following objectives:
- Reorganize algorithms to reduce communication across all memory hierarchies.
- Attain the lower-bound on communication when possible.
The following simple example[1] demonstrates how these are achieved.
Matrix Multiplication Example
Let A, B and C be square matrices of order n x n. The following naive algorithm implements C = C + A * B:

for i = 1 to n
for j = 1 to n
for k = 1 to n
C(i,j) = C(i,j) + A(i,k) * B(k,j)
Arithmetic cost (time-complexity): n² (2n-1) for sufficiently large n or O(n³).
Rewriting this algorithm with communication cost labelled at each step
for i = 1 to n
{read row i of A into fast memory} - n² reads
for j = 1 to n
{read C(i,j) into fast memory} - n² reads
{read column j of B into fast memory} - n³ reads
for k = 1 to n
C(i,j) = C(i,j) + A(i,k) * B(k,j)
{write C(i,j) back to slow memory} - n² writes
Fast memory may be defined as the local processor memory (CPU cache) of size M and slow memory may be defined as the DRAM.
Communication cost (reads/writes): n³ + 3n² or O(n³)
Since total running time = γ*O(n³) + β*O(n³) and β >> γ the communication cost is dominant. The Blocked (Tiled) Matrix Multiplication algorithm[1] reduces this dominant term.
Blocked (Tiled) Matrix Multiplication
Consider A,B,C to be n/b-by-n/b matrices of b-by-b sub-blocks where b is called the block size; assume 3 b-by-b blocks fit in fast memory.
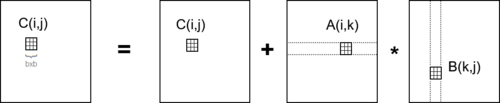
for i = 1 to n/b
for j = 1 to n/b
{read block C(i,j) into fast memory} - b² × (n/b)² = n² reads
for k = 1 to n/b
{read block A(i,k) into fast memory} - b² × (n/b)³ = n³/b reads
{read block B(k,j) into fast memory} - b² × (n/b)³ = n³/b reads
C(i,j) = C(i,j) + A(i,k) * B(k,j) - {do a matrix multiply on blocks}
{write block C(i,j) back to slow memory} - b² × (n/b)² = n² writes
Communication cost: 2n³/b + 2n² reads/writes << 2n³ arithmetic cost
Making b as large possible: 3b2 ≤ M We achieve the following communication lowerbound: 31/2n3/M1/2 + 2n2 or Ω(no. of FLOPs / M1/2 )
Previous approaches for reducing communication
Most of the approaches investigated in the past to address this problem rely on scheduling or tuning techniques that aim at overlapping communication with computation. However, this approach can lead to an improvement of at most a factor of two. Ghosting is a different technique for reducing communication, in which a processor stores and computes redundantly data from neighboring processors for future computations. Cache-oblivious algorithms represent a different approach introduced in 1999 for Fast Fourier Transforms,[5] and then extended to graph algorithms, dynamic programming, etc. They were also applied to several operations in linear algebra[6][7][8] as dense LU and QR factorizations. The design of architecture specific algorithms is another approach that can be used for reducing the communication in parallel algorithms, and there are many examples in the literature of algorithms that are adapted to a given communication topology.[9]
References
- 1 2 3 4 5 Demmel, Jim. "Communication avoiding algorithms." 2012 SC Companion: High Performance Computing, Networking Storage and Analysis. IEEE, 2012.
- ↑ Demmel, James, and Kathy Yelick. "Communication Avoiding (CA) and Other Innovative Algorithms." The Berkeley Par Lab: Progress in the Parallel Computing Landscape: 243-250.
- ↑ Bergman, Keren, et al. "Exascale computing study: Technology challenges in exascale computing systems." Defense Advanced Research Projects Agency Information Processing Techniques Office (DARPA IPTO), Tech. Rep 15 (2008).
- ↑ Shalf, John, Sudip Dosanjh, and John Morrison. "Exascale computing technology challenges." High Performance Computing for Computational Science–VECPAR 2010. Springer Berlin Heidelberg, 2011. 1-25.
- ↑ M. Frigo, C. E. Leiserson, H. Prokop, and S. Ramachandran, “Cacheoblivious algorithms,” In FOCS ’99: Proceedings of the 40th Annual Symposium on Foundations of Computer Science, 1999. IEEE Computer Society.
- ↑ S. Toledo, “Locality of reference in LU Decomposition with partial pivoting,” SIAM J. Matrix Anal. Appl., vol. 18, no. 4, 1997.
- ↑ F. Gustavson, “Recursion Leads to Automatic Variable Blocking for Dense Linear-Algebra Algorithms,” IBM Journal of Research and Development, vol. 41, no. 6, pp. 737–755, 1997.
- ↑ E. Elmroth, F. Gustavson, I. Jonsson, and B. Kagstrom, “Recursive blocked algorithms and hybrid data structures for dense matrix library software,” SIAM Review, vol. 46, no. 1, pp. 3–45, 2004.
- ↑ Grigori, Laura. "Introduction to communication avoiding linear algebra algorithms in high performance computing.