Replication (computing)
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
Terminology
One speaks of:
- data replication if the same data is stored on multiple storage devices,
- computation replication if the same computing task is executed many times.
A computational task is typically replicated in space, i.e. executed on separate devices, or it could be replicated in time, if it is executed repeatedly on a single device. Replication in space or in time is often linked to scheduling algorithms [1]
The access to a replicated entity is typically uniform with access to a single, non-replicated entity. The replication itself should be transparent to an external user. Also, in a failure scenario, a failover of replicas is hidden as much as possible. The latter refers to data replication with respect to Quality of Service (QoS) aspects.[2]
Computer scientists talk about active and passive replication in systems that replicate data or services:
- active replication is performed by processing the same request at every replica.
- passive replication involves processing each single request on a single replica and then transferring its resultant state to the other replicas.
If at any time one master replica is designated to process all the requests, then we are talking about the primary-backup scheme (master-slave scheme) predominant in high-availability clusters. On the other side, if any replica processes a request and then distributes a new state, then this is a multi-primary scheme (called multi-master in the database field). In the multi-primary scheme, some form of distributed concurrency control must be used, such as distributed lock manager.
Load balancing differs from task replication, since it distributes a load of different (not the same) computations across machines, and allows a single computation to be dropped in case of failure. Load balancing, however, sometimes uses data replication (especially multi-master replication) internally, to distribute its data among machines.
Backup differs from replication in that it saves a copy of data unchanged for a long period of time. Replicas, on the other hand, undergo frequent updates and quickly lose any historical state. Replication is one of the oldest and most important topics in the overall area of distributed systems.
Whether one replicates data or computation, the objective is to have some group of processes that handle incoming events. If we replicate data, these processes are passive and operate only to maintain the stored data, reply to read requests, and apply updates. When we replicate computation, the usual goal is to provide fault-tolerance. For example, a replicated service might be used to control a telephone switch, with the objective of ensuring that even if the primary controller fails, the backup can take over its functions. But the underlying needs are the same in both cases: by ensuring that the replicas see the same events in equivalent orders, they stay in consistent states and hence any replica can respond to queries.
Replication models in distributed systems
A number of widely cited models exist for data replication, each having its own properties and performance:
- Transactional replication. This is the model for replicating transactional data, for example a database or some other form of transactional storage structure. The one-copy serializability model is employed in this case, which defines legal outcomes of a transaction on replicated data in accordance with the overall ACID properties that transactional systems seek to guarantee.
- State machine replication. This model assumes that replicated process is a deterministic finite automaton and that atomic broadcast of every event is possible. It is based on a distributed computing problem called distributed consensus and has a great deal in common with the transactional replication model. This is sometimes mistakenly used as synonym of active replication. State machine replication is usually implemented by a replicated log consisting of multiple subsequent rounds of the Paxos algorithm. This was popularized by Google's Chubby system, and is the core behind the open-source Keyspace data store.[3][4]
- Virtual synchrony. This computational model is used when a group of processes cooperate to replicate in-memory data or to coordinate actions. The model defines a distributed entity called a process group. A process can join a group, and is provided with a checkpoint containing the current state of the data replicated by group members. Processes can then send multicasts to the group and will see incoming multicasts in the identical order. Membership changes are handled as a special multicast that delivers a new membership view to the processes in the group.
Database replication
Database replication can be used on many database management systems, usually with a master/slave relationship between the original and the copies. The master logs the updates, which then ripple through to the slaves. The slave outputs a message stating that it has received the update successfully, thus allowing the sending (and potentially re-sending until successfully applied) of subsequent updates.
Multi-master replication, where updates can be submitted to any database node, and then ripple through to other servers, is often desired, but introduces substantially increased costs and complexity which may make it impractical in some situations. The most common challenge that exists in multi-master replication is transactional conflict prevention or resolution. Most synchronous or eager replication solutions do conflict prevention, while asynchronous solutions have to do conflict resolution. For instance, if a record is changed on two nodes simultaneously, an eager replication system would detect the conflict before confirming the commit and abort one of the transactions. A lazy replication system would allow both transactions to commit and run a conflict resolution during resynchronization.[5] The resolution of such a conflict may be based on a timestamp of the transaction, on the hierarchy of the origin nodes or on much more complex logic, which decides consistently on all nodes.
Database replication becomes difficult when it scales up. Usually, the scale up goes with two dimensions, horizontal and vertical: horizontal scale-up has more data replicas, vertical scale-up has data replicas located further away in distance. Problems raised by horizontal scale-up can be alleviated by a multi-layer multi-view access protocol. Vertical scale-up causes fewer problems in that internet reliability and performance are improving.[6]
When data is replicated between database servers, so that the information remains consistent throughout the database system and users cannot tell or even know which server in the DBMS they are using, the system is said to exhibit replication transparency.
Disk storage replication
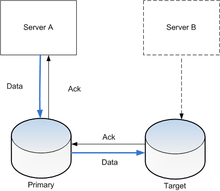
Active (real-time) storage replication is usually implemented by distributing updates of a block device to several physical hard disks. This way, any file system supported by the operating system can be replicated without modification, as the file system code works on a level above the block device driver layer. It is implemented either in hardware (in a disk array controller) or in software (in a device driver).
The most basic method is disk mirroring, typical for locally connected disks. The storage industry narrows the definitions, so mirroring is a local (short-distance) operation. A replication is extendable across a computer network, so the disks can be located in physically distant locations, and the master-slave database replication model is usually applied. The purpose of replication is to prevent damage from failures or disasters that may occur in one location, or in case such events do occur, improve the ability to recover. For replication, latency is the key factor because it determines either how far apart the sites can be or the type of replication that can be employed.
The main characteristic of such cross-site replication is how write operations are handled:
- Synchronous replication - guarantees "zero data loss" by the means of atomic write operation, i.e. write either completes on both sides or not at all. Write is not considered complete until acknowledgement by both local and remote storage. Most applications wait for a write transaction to complete before proceeding with further work, hence overall performance decreases considerably. Inherently, performance drops proportionally to distance, as latency is caused by speed of light. For 10 km distance, the fastest possible roundtrip takes 67 μs, whereas nowadays a whole local cached write completes in about 10-20 μs.
- An often-overlooked aspect of synchronous replication is the fact that failure of remote replica, or even just the interconnection, stops by definition any and all writes (freezing the local storage system). This is the behaviour that guarantees zero data loss. However, many commercial systems at such potentially dangerous point do not freeze, but just proceed with local writes, losing the desired zero recovery point objective.
- The main difference between synchronous and asynchronous volume replication is that synchronous replication needs to wait for the destination server in any write operation.
- Asynchronous replication - write is considered complete as soon as local storage acknowledges it. Remote storage is updated, but probably with a small lag. Performance is greatly increased, but in case of losing a local storage, the remote storage is not guaranteed to have the current copy of data and most recent data may be lost.
- Semi-synchronous replication - this usually means that a write is considered complete as soon as local storage acknowledges it and a remote server acknowledges that it has received the write either into memory or to a dedicated log file. The actual remote write is not performed immediately but is performed asynchronously, resulting in better performance than synchronous replication but offering no guarantee of durability.
- Point-in-time replication - introduces periodic snapshots that are replicated instead of primary storage. If the replicated snapshots are pointer-based, then during replication only the changed data is moved not the entire volume. Using this method, replication can occur over smaller, less expensive bandwidth links such as iSCSI or T1 instead of fiber optic lines.
To address the limits imposed by latency, techniques of WAN optimization can be applied to the link.
Implementations
Many distributed filesystems use replication to ensure fault tolerance and avoid a single point of failure. See the lists of distributed fault-tolerant file systems and distributed parallel fault-tolerant file systems.
File-based replication
File-based replication is replicating files at a logical level rather than replicating at the storage block level. There are many different ways of performing this. Unlike with storage-level replication, the solutions almost exclusively rely on software.
Capture with a kernel driver
With the use of a kernel driver (specifically a filter driver), that intercepts calls to the filesystem functions, any activity is captured immediately as it occurs. This utilises the same type of technology that real time active virus checkers employ. At this level, logical file operations are captured like file open, write, delete, etc. The kernel driver transmits these commands to another process, generally over a network to a different machine, which will mimic the operations of the source machine. Like block-level storage replication, the file-level replication allows both synchronous and asynchronous modes. In synchronous mode, write operations on the source machine are held and not allowed to occur until the destination machine has acknowledged the successful replication. Synchronous mode is less common with file replication products although a few solutions exist.
File level replication solution yield a few benefits. Firstly because data is captured at a file level it can make an informed decision on whether to replicate based on the location of the file and the type of file. Hence unlike block-level storage replication where a whole volume needs to be replicated, file replication products have the ability to exclude temporary files or parts of a filesystem that hold no business value. This can substantially reduce the amount of data sent from the source machine as well as decrease the storage burden on the destination machine. A further benefit to decreasing bandwidth is the data transmitted can be more granular than with block-level replication. If an application writes 100 bytes, only the 100 bytes are transmitted not a complete disk block which is generally 4096 bytes.
On a negative side, as this is a software only solution, it requires implementation and maintenance on the operating system level, and uses some of machine's processing power (CPU).
File system journal replication
Similarly to database transaction logs, many file systems have the ability to journal their activity. The journal can be sent to another machine, either periodically or in real time by streaming. On the replica side, the journal can be used to play back file system modifications.
One of the notable implementations is Microsoft's System Center Data Protection Manager (DPM), which performs periodical updates but does not offer real-time replication.
Batch replication
This is the process of comparing the source and destination filesystems and ensuring that the destination matches the source. The key benefit is that such solutions are generally free or inexpensive. The downside is that the process of synchronizing them is quite system-intensive, and consequently this process generally runs infrequently.
One of the notable implementations is rsync.
Distributed shared memory replication
Another example of using replication appears in distributed shared memory systems, where it may happen that many nodes of the system share the same page of the memory - which usually means, that each node has a separate copy (replica) of this page.
Primary-backup and multi-primary replication
Many classical approaches to replication are based on a primary/backup model where one device or process has unilateral control over one or more other processes or devices. For example, the primary might perform some computation, streaming a log of updates to a backup (standby) process, which can then take over if the primary fails. This approach is the most common one for replicating databases, despite the risk that if a portion of the log is lost during a failure, the backup might not be in a state identical to the one the primary was in, and transactions could then be lost.
A weakness of primary/backup schemes is that in settings where both processes could have been active, only one is actually performing operations. We're gaining fault-tolerance but spending twice as much money to get this property. For this reason, starting in the period around 1985, the distributed systems research community began to explore alternative methods of replicating data. An outgrowth of this work was the emergence of schemes in which a group of replicas could cooperate, with each process backup up the others, and each handling some share of the workload.
Jim Gray, a towering figure[7] within the database community, analyzed multi-primary replication schemes under the transactional model and ultimately published a widely cited paper skeptical of the approach "The Dangers of Replication and a Solution". In a nutshell, he argued that unless data splits in some natural way so that the database can be treated as n disjoint sub-databases, concurrency control conflicts will result in seriously degraded performance and the group of replicas will probably slow down as a function of n. Indeed, he suggests that the most common approaches are likely to result in degradation that scales as O(n³). His solution, which is to partition the data, is only viable in situations where data actually has a natural partitioning key.
The situation is not always so bleak. For example, in the 1985–87 period, the virtual synchrony model was proposed and emerged as a widely adopted standard (it was used in the Isis Toolkit, Horus, Transis, Ensemble, Totem, Spread, C-Ensemble, Phoenix and Quicksilver systems, and is the basis for the CORBA fault-tolerant computing standard; the model is also used in IBM Websphere to replicate business logic and in Microsoft's Windows Server 2008 enterprise clustering technology). Virtual synchrony permits a multi-primary approach in which a group of processes cooperate to parallelize some aspects of request processing. The scheme can only be used for some forms of in-memory data, but when feasible, provides linear speedups in the size of the group.
A number of modern products support similar schemes. For example, the Spread Toolkit supports this same virtual synchrony model and can be used to implement a multi-primary replication scheme; it would also be possible to use C-Ensemble or Quicksilver in this manner. WANdisco permits active replication where every node on a network is an exact copy or replica and hence every node on the network is active at one time; this scheme is optimized for use in a wide area network.
See also
References
- ↑ Mansouri, Najme, GholamHosein Dastghaibyfard, and Ehsan Mansouri. "Combination of data replication and scheduling algorithm for improving data availability in Data Grids." Journal of Network and Computer Applications (2013)
- ↑ V. Andronikou, K. Mamouras, K. Tserpes, D. Kyriazis, T. Varvarigou, Dynamic QoS-aware Data Replication in Grid Environments, Elsevier Future Generation Computer Systems - The International Journal of Grid Computing and eScience, 2012
- ↑ Marton Trencseni, Attila Gazso (2009). "Keyspace: A Consistently Replicated, Highly-Available Key-Value Store". Retrieved 2010-04-18.
- ↑ Mike Burrows (2006). "The Chubby Lock Service for Loosely-Coupled Distributed Systems". Retrieved 2010-04-18.
- ↑ "Conflict Resolution". ITTIA. Retrieved 21 October 2016.
- ↑ Dragan Simic; Srecko Ristic; Slobodan Obradovic (April 2007). "Measurement of the Achieved Performance Levels of the WEB Applications With Distributed Relational Database" (PDF). Electronics and Energetics. Facta Universitatis. p. 31–43. Retrieved 30 January 2014.
- ↑ Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data: SIGMOD '99, Philadelphia, PA, USA; June 1–3, 1999, Volume 28; p. 3.