Distributed file system for cloud
A distributed file system for cloud is a file system that allows many clients to have access to data and supports operations (create, delete, modify, read, write) on that data. Each data file may be partitioned into several parts called chunks. Each chunk may be stored on different remote machines, facilitating the parallel execution of applications. Typically, data is stored in files in a hierarchical tree, where the nodes represent directories. There are several ways to share files in a distributed architecture: each solution must be suitable for a certain type of application, depending on how complex the application is. Meanwhile, the security of the system must be ensured. Confidentiality, availability and integrity are the main keys for a secure system.
Users can share computing resources through the Internet thanks to cloud computing which is typically characterized by scalable and elastic resources - such as physical servers, applications and any services that are virtualized and allocated dynamically. Synchronization is required to make sure that all devices are up-to-date.
Distributed file systems enable many big, medium, and small enterprises to store and access their remote data as they do local data, facilitating the use of variable resources.
Overview
History
Today, there are many implementations of distributed file systems. The first file servers were developed by researchers in the 1970s. Sun Microsystem's Network File System became available in the 1980s. Before that, people who wanted to share files used the sneakernet method, physically transporting files on storage media from place to place. Once computer networks started to proliferate, it became obvious that the existing file systems had many limitations and were unsuitable for multi-user environments. Users initially used FTP to share files.[1] FTP first ran on the PDP-10 at the end of 1973. Even with FTP, files needed to be copied from the source computer onto a server and then from the server onto the destination computer. Users were required to know the physical addresses of all computers involved with the file sharing.[2]
Supporting techniques
Modern data centers must support large, heterogenous environments, consisting of large numbers of computers of varying capacities. Cloud computing coordinates the operation of all such systems, with techniques such as data center networking (DCN), the MapReduce framework, which supports data-intensive computing applications in parallel and distributed systems, and virtualization techniques that provide dynamic resource allocation, allowing multiple operating systems to coexist on the same physical server.
Applications
Cloud computing provides large-scale computing thanks to its ability to provide the needed CPU and storage resources to the user with complete transparency. This makes cloud computing particularly suited to support different types of applications that require large-scale distributed processing. This data-intensive computing needs a high performance file system that can share data between virtual machines (VM).[3]
Cloud computing dynamically allocates the needed resources, releasing them once a task is finished, requiring users to pay only for needed services, often via a service-level agreement. Cloud computing and cluster computing paradigms are becoming increasingly important to industrial data processing and scientific applications such as astronomy and physics, which frequently require the availability of large numbers of computers to carry out experiments.[4]
Architectures
Most distributed file systems are built on the client-server architecture, but other, decentralized, solutions exist as well.

Client-server architecture
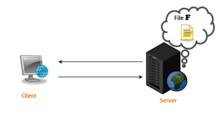
Network File System (NFS) uses a client-server architecture, which allows sharing files between a number of machines on a network as if they were located locally, providing a standardized view. The NFS protocol allows heterogeneous clients' processes, probably running on different machines and under different operating systems, to access files on a distant server, ignoring the actual location of files. Relying on a single server results in the NFS protocol suffering from potentially low availability and poor scalability. Using multiple servers does not solve the availability problem since each server is working independently.[5] The model of NFS is a remote file service. This model is also called the remote access model, which is in contrast with the upload/download model:
- Remote access model: Provides transparency, the client has access to a file. He send requests to the remote file (while the file remains on the server).[6]
- Upload/download model: The client can access the file only locally. It means that the client has to download the file, make modifications, and upload it again, to be used by others' clients.
The file system used by NFS is almost the same as the one used by Unix systems. Files are hierarchically organized into a naming graph in which directories and files are represented by nodes.
Cluster-based architectures
A cluster-based architecture ameliorates some of the issues in client-server architectures, improving the execution of applications in parallel. The technique used here is file-striping: a file is split into multiple chunks, which are "striped" across several storage servers. The goal is to allow access to different parts of a file in parallel. If the application does not benefit from this technique, then it would be more convenient to store different files on different servers. However, when it comes to organizing a distributed file system for large data centers, such as Amazon and Google, that offer services to web clients allowing multiple operations (reading, updating, deleting,...) to a large number of files distributed among a large number of computers, then cluster-based solutions become more beneficial. Note that having a large number of computers may mean more hardware failures.[7] Two of the most widely used distributed file systems (DFS) of this type are the Google File System (GFS) and the Hadoop Distributed File System (HDFS). The file systems of both are implemented by user level processes running on top of a standard operating system (Linux in the case of GFS).[8]
Design principles
Goals
Google File System (GFS) and Hadoop Distributed File System (HDFS) are specifically built for handling batch processing on very large data sets. For that, the following hypotheses must be taken into account:[9]
- High availability: the cluster can contain thousands of file servers and some of them can be down at any time
- A server belongs to a rack, a room, a data center, a country, and a continent, in order to precisely identify its geographical location
- The size of a file can vary from many gigabytes to many terabytes. The file system should be able to support a massive number of files
- The need to support append operations and allow file contents to be visible even while a file is being written
- Communication is reliable among working machines: TCP/IP is used with a remote procedure call RPC communication abstraction. TCP allows the client to know almost immediately when there is a problem and a need to make a new connection.[10]
Load balancing
Load balancing is essential for efficient operation in distributed environments. It means distributing work among different servers,[11] fairly, in order to get more work done in the same amount of time and to serve clients faster. In a system containing N chunkservers in a cloud (N being 1000, 10000, or more), where a certain number of files are stored, each file is split into several parts or chunks of fixed size (for example, 64 megabytes), the load of each chunkserver being proportional to the number of chunks hosted by the server.[12] In a load-balanced cloud, resources can be efficiently used while maximizing the performance of MapReduce-based applications.
Load rebalancing
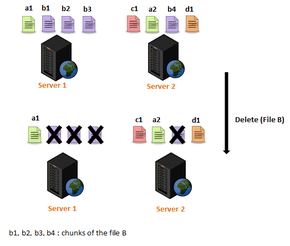
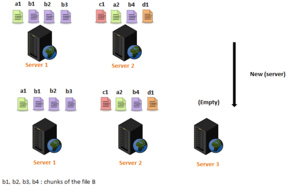
In a cloud computing environment, failure is the norm,[13][14] and chunkservers may be upgraded, replaced, and added to the system. Files can also be dynamically created, deleted, and appended. That leads to load imbalance in a distributed file system, meaning that the file chunks are not distributed equitably between the servers.
Distributed file systems in clouds such as GFS and HDFS rely on central or master servers or nodes (Master for GFS and NameNode for HDFS) to manage the metadata and the load balancing. The master rebalances replicas periodically: data must be moved from one DataNode/chunkserver to another if free space on the first server falls below a certain threshold.[15] However, this centralized approach can become a bottleneck for those master servers, if they become unable to manage a large number of file accesses, as it increases their already heavy loads. The load rebalance problem is NP-hard.[16]
In order to get large number of chunkservers to work in collaboration, and to solve the problem of load balancing in distributed file systems, several approaches have been proposed, such as reallocating file chunks so that the chunks can be distributed as uniformly as possible while reducing the movement cost as much as possible.[12]
Google file system
Description
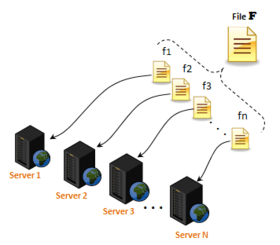
Google, one of the biggest internet companies, has created its own distributed file system, named Google File System (GFS), to meet the rapidly growing demands of Google's data processing needs, and it is used for all cloud services. GFS is a scalable distributed file system for data-intensive applications. It provides fault-tolerant, high-performance data storage a large number of clients accessing it simultaneously.
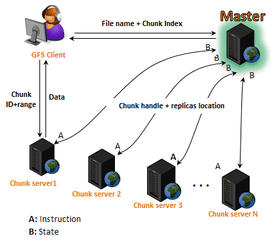
GFS uses MapReduce, which allows users to create programs and run them on multiple machines without thinking about parallelization and load-balancing issues. GFS architecture is based on having a single master server for multiple chunkservers and multiple clients.[17]
The master server running in dedicated node is responsible for coordinating storage resources and managing files's metadata (the equivalent of, for example, inodes in classical file systems).[9] Each file is split to multiple chunks of 64 megabytes. Each chunk is stored in a chunk server. A chunk is identified by a chunk handle, which is a globally unique 64-bit number that is assigned by the master when the chunk is first created.
The master maintains all of the files's metadata, including file names, directories, and the mapping of files to the list of chunks that contain each file’s data. The metadata is kept in the master server's main memory, along with the mapping of files to chunks. Updates to this data are logged to an operation log on disk. This operation log is replicated onto remote machines. When the log become too large, a checkpoint is made and the main-memory data is stored in a B-tree structure to facilitate mapping back into main memory.[18]
Fault tolerance
To facilitate fault tolerance, each chunk is replicated onto multiple (default, three) chunk servers.[19] A chunk is available on at least one chunk server. The advantage of this scheme is simplicity. The master is responsible for allocating the chunk servers for each chunk and is contacted only for metadata information. For all other data, the client has to interact with the chunk servers.
The master keeps track of where a chunk is located. However, it does not attempt to maintain the chunk locations precisely but only occasionally contacts the chunk servers to see which chunks they have stored.[20] This allows for scalability, and helps prevent bottlenecks due to increased workload.[21]
In GFS, most files are modified by appending new data and not overwriting existing data. Once written, the files are usually only read sequentially rather than randomly, and that makes this DFS the most suitable for scenarios in which many large files are created once but read many times.[22][23]
File processing
When a client wants to write-to/update a file, the master will assign a replica, which will be the primary replica if it is the first modification. The process of writing is composed of two steps:[9]
- Sending: First, and by far the most important, the client contacts the master to find out which chunk servers hold the data. The client is given a list of replicas identifying the primary and secondary chunk servers. The client then contacts the nearest replica chunk server, and sends the data to it. This server will send the data to the next closest one, which then forwards it to yet another replica, and so on. The data is then propagated and cached in memory but not yet written to a file.
- Writing: When all the replicas have received the data, the client sends a write request to the primary chunk server, identifying the data that was sent in the sending phase. The primary server will then assign a sequence number to the write operations that it has received, apply the writes to the file in serial-number order, and forward the write requests in that order to the secondaries. Meanwhile, the master is kept out of the loop.
Consequently, we can differentiate two types of flows: the data flow and the control flow. Data flow is associated with the sending phase and control flow is associated to the writing phase. This assures that the primary chunk server takes control of the write order. Note that when the master assigns the write operation to a replica, it increments the chunk version number and informs all of the replicas containing that chunk of the new version number. Chunk version numbers allow for update error-detection, if a replica wasn't updated because its chunk server was down.[24]
Some new Google applications did not work well with the 64-megabyte chunk size. To solve that problem, GFS started, in 2004, to implement the BigTable approach.[25]
Hadoop distributed file system
HDFS, developed by the Apache Software Foundation, is a distributed file system designed to hold very large amounts of data (terabytes or even petabytes). Its architecture is similar to GFS, i.e. a master/slave architecture. The HDFS is normally installed on a cluster of computers. The design concept of Hadoop is informed by Google's, with Google File System, Google MapReduce and BigTable, being implemented by Hadoop Distributed File System (HDFS), Hadoop MapReduce, and Hadoop Base (HBase) respectively.[26] Like GFS, HDFS is suited for scenarios with write-once-read-many file access, and supports file appends and truncates in lieu of random reads and writes to simplify data coherency issues. [27]
An HDFS cluster consists of a single NameNode and several DataNode machines. The NameNode, a master server, manages and maintains the metadata of storage DataNodes in its RAM. DataNodes manage storage attached to the nodes that they run on. NameNode and DataNode are software designed to run on everyday-use machines, which typically run under a GNU/Linux OS. HDFS can be run on any machine that supports Java and therefore can run either a NameNode or the Datanode software.[28]
On an HDFS cluster, a file is split into one or more equal-size blocks, except for the possibility of the last block being smaller. Each block is stored on multiple DataNodes, and each may be replicated on multiple DataNodes to guarantee availability. By default, each block is replicated three times, a process called "Block Level Replication".[29]
The NameNode manages the file system namespace operations such as opening, closing, and renaming files and directories, and regulates file access. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for servicing read and write requests from the file system’s clients, managing the block allocation or deletion, and replicating blocks.[30]
When a client wants to read or write data, it contacts the NameNode and the NameNode checks where the data should be read from or written to. After that, the client has the location of the DataNode and can send read or write requests to it.
The HDFS is typically characterized by its compatibility with data rebalancing schemes. In general, managing the free space on a DataNode is very important. Data must be moved from one DataNode to another, if free space is not adequate; and in the case of creating additional replicas, data should be moved to assure system balance.[29]
Other examples
Distributed file systems can be optimized for different purposes. Some, such as those designed for internet services, including GFS, are optimized for scalability. Other designs for distributed file systems support performance-0intensive applications usually executed in parallel.[31] Some examples include: MapR File System (MapR-FS), Ceph-FS, Fraunhofer File System (BeeGFS), Lustre File System, IBM General Parallel File System (GPFS), and Parallel Virtual File System.
MapR-FS is a distributed file system that is the basis of the MapR Converged Platform, with capabilities for distributed file storage, a NoSQL database with multiple APIs, and an integrated message streaming system. MapR-FS is optimized for scalability, performance, reliability, and availability. Its file storage capability is compatible with the Apache Hadoop Distributed File System (HDFS) API but with several design characteristics that distinguish it from HDFS. Among the most notable differences are that MapR-FS is a fully read/write filesystem with metadata for files and directories distributed across the namespace, so there is no NameNode.[32][33][34][35][36]
Ceph-FS is a distributed file system that provides excellent performance and reliability.[37] It answers the challenges of dealing with huge files and directories, coordinating the activity of thousands of disks, providing parallel access to metadata on a massive scale, manipulating both scientific and general-purpose workloads, authenticating and encrypting on a large scale, and increasing or decreasing dynamically due to frequent device decommissioning, device failures, and cluster expansions.[38]
BeeGFS is the high-performance parallel file system from the Fraunhofer Competence Centre for High Performance Computing. The distributed metadata architecture of BeeGFS has been designed to provide the scalability and flexibility needed to run HPC and similar applications with high I/O demands.[39]
Lustre File System has been designed and implemented to deal with the issue of bottlenecks traditionally found in distributed systems. Lustre is characterized by its efficiency, scalability, and redundancy.[40] GPFS was also designed with the goal of removing such bottlenecks.[41]
Communication
High performance of distributed file systems requires efficient communication between computing nodes and fast access to the storage systems. Operations such as open, close, read, write, send, and receive need to be fast, to ensure that performance. For example, each read or write request accesses disk storage, which introduces seek, rotational, and network latencies.[42]
The data communication (send/receive) operations transfer data from the application buffer to the machine kernel, TCP controlling the process and being implemented in the kernel. However, in case of network congestion or errors, TCP may not send the data directly. While transferring data from a buffer in the kernel to the application, the machine does not read the byte stream from the remote machine. In fact, TCP is responsible for buffering the data for the application.[43]
Choosing the buffer-size, for file reading and writing, or file sending and receiving, is done at the application level. The buffer is maintained using a circular linked list.[44] It consists of a set of BufferNodes. Each BufferNode has a DataField. The DataField contains the data and a pointer called NextBufferNode that points to the next BufferNode. To find the current position, two pointers are used: CurrentBufferNode and EndBufferNode, that represent the position in the BufferNode for the last write and read positions. If the BufferNode has no free space, it will send a wait signal to the client to wait until there is available space.[45]
Cloud-based Synchronization of Distributed File System
More and more users have multiple devices with ad hoc connectivity. The data sets replicated on these devices need to be synchronized among an arbitrary number of servers. This is useful for backups and also for offline operation. Indeed, when user network conditions are not good, then the user device will selectively replicate a part of data that will be modified later and off-line. Once the network conditions become good, the device is synchronized.[46] Two approaches exist to tackle the distributed synchronization issue: user-controlled peer-to-peer synchronization and cloud master-replica synchronization.[46]
- user-controlled peer-to-peer: software such as rsync must be installed in all users' computers that contain their data. The files are synchronized by peer-to-peer synchronization where users must specify network addresses and synchronization parameters, and is thus a manual process.
- cloud master-replica synchronization: widely used by cloud services, in which a master replica is maintained in the cloud, and all updates and synchronization operations are to this master copy, offering a high level of availability and reliability in case of failures.
Security keys
In cloud computing, the most important security concepts are confidentiality, integrity, and availability ("CIA"). Confidentiality becomes indispensable in order to keep private data from being disclosed. Integrity ensures that data is not corrupted.[47]
Confidentiality
Confidentiality means that data and computation tasks are confidential: neither cloud provider nor other clients can access the client's data. Much research has been done about confidentiality, because it is one of the crucial points that still presents challenges for cloud computing. A lack of trust in the cloud providers is also a related issue.[48] The infrastructure of the cloud must ensure that customers' data will not be accessed by unauthorized parties.
The environment becomes insecure if the service provider can do all of the following:[49]
- locate the consumer's data in the cloud
- access and retrieve consumer's data
- understand the meaning of the data (types of data, functionalities and interfaces of the application and format of the data).
The geographic location of data helps determine privacy and confidentiality. The location of clients should be taken into account. For example, clients in Europe won't be interested in using datacenters located in United States, because that affects the guarantee of the confidentiality of data. In order to deal with that problem, some cloud computing vendors have included the geographic location of the host as a parameter of the service-level agreement made with the customer,[50] allowing users to choose themselves the locations of the servers that will host their data.
Another approach to confidentiality involves data encryption.[51] Otherwise, there will be serious risk of unauthorized use. A variety of solutions exists, such as encrypting only sensitive data,[52] and supporting only some operations, in order to simplify computation.[53] Furthermore, cryptographic techniques and tools as FHE, are used to preserve privacy in the cloud.[47]
Integrity
Integrity in cloud computing implies data integrity as well as computing integrity. Such integrity means that data has to be stored correctly on cloud servers and, in case of failures or incorrect computing, that problems have to be detected.
Data integrity can be affected by malicious events or from administration errors (e.g. during backup and restore, data migration, or changing memberships in P2P systems).[54]
Integrity is easy to achieve using cryptography (typically through message-authentication code, or MACs, on data blocks).[55]
There exist checking mechanisms that effect data integrity. For instance:
- HAIL (High-Availability and Integrity Layer) is a distributed cryptographic system that allows a set of servers to prove to a client that a stored file is intact and retrievable.[56]
- Hach PORs (proofs of retrievability for large files)[57] is based on a symmetric cryptographic system, where there is only one verification key that must be stored in a file to improve its integrity. This method serves to encrypt a file F and then generate a random string named "sentinel" that must be added at the end of the encrypted file. The server cannot locate the sentinel, which is impossible differentiate from other blocks, so a small change would indicate whether the file has been changed or not.
- PDP (provable data possession) checking is a class of efficient and practical methods that provide an efficient way to check data integrity on untrusted servers:
- PDP:[58] Before storing the data on a server, the client must store, locally, some meta-data. At a later time, and without downloading data, the client is able to ask the server to check that the data has not been falsified. This approach is used for static data.
- Scalable PDP:[59] This approach is premised upon a symmetric-key, which is more efficient than public-key encryption. It supports some dynamic operations (modification, deletion, and append) but it cannot be used for public verification.
- Dynamic PDP:[60] This approach extends the PDP model to support several update operations such as append, insert, modify, and delete, which is well suited for intensive computation.
Availability
Availability is generally effected by replication.[61][62] [63][64] Meanwhile, consistency must be guaranteed. However, consistency and availability cannot be achieved at the same time; each is prioritized at some sacrifice of the other. A balance must be struck. [65]
Data must have an identity to be accessible. For instance, Skute [61] is a mechanism based on key/value storage that allows dynamic data allocation in an efficient way. Each server must be identified by a label in the form continent-country-datacenter-room-rack-server. The server can reference multiple virtual nodes, with each node having a selection of data (or multiple partitions of multiple data). Each piece of data is identified by a key space which is generated by a one-way cryptographic hash function (e.g. MD5) and is localised by the hash function value of this key. The key space may be partitioned into multiple partitions with each partition referring to a piece of data. To perform replication, virtual nodes must be replicated and referenced by other servers. To maximize data durability and data availability, the replicas must be placed on different servers and every server should be in a different geographical location, because data availability increases with geographical diversity. The process of replication includes an evaluation of space availability, which must be above a certain minimum thresh-hold on each chunk server. Otherwise, data are replicated to another chunk server. Each partition, i, has an availability value represented by the following formula:

where are the servers hosting the replicas, and are the confidence of servers and (relying on technical factors such as hardware components and non-technical ones like the economic and political situation of a country) and the diversity is the geographical distance between and .[66]






Replication is a great solution to ensure data availability, but it costs too much in terms of memory space.[67] DiskReduce[67] is a modified version of HDFS that's based on RAID technology (RAID-5 and RAID-6) and allows asynchronous encoding of replicated data. Indeed, there is a background process which looks for widely replicated data and deletes extra copies after encoding it. Another approach is to replace replication with erasure coding.[68] In addition, to ensure data availability there are many approaches that allow for data recovery. In fact, data must be coded, and if it is lost, it can be recovered from fragments which were constructed during the coding phase.[69] Some other approaches that apply different mechanisms to guarantee availability are: Reed-Solomon code of Microsoft Azure and RaidNode for HDFS. Also Google is still working on a new approach based on an erasure-coding mechanism.[70]
There is no RAID implementation for cloud storage.[68]
Economic aspects
The cloud computing economy is growing rapidly. The US government has decided to spend 40% of its compound annual growth rate (CAGR), expected to be 7 billion dollars by 2015.[71]
More and more companies have been utilizing cloud computing to manage the massive amount of data and to overcome the lack of storage capacity, and because it enables them to use such resources as a service, ensuring that their computing needs will be met without having to invest in infrastructure (Pay-as-you-go model).[72]
Every application provider has to periodically pay the cost of each server where replicas of data are stored. The cost of a server is determined by the quality of the hardware, the storage capacities, and its query-processing and communication overhead.[73] Cloud computing allows providers to scale their services according to client demands.
The pay-as-you-go model has also eased the burden on startup companies that wish to benefit from compute-intensive business. Cloud computing also offers an opportunity to many third-world countries that wouldn't have such computing resources otherwise. Cloud computing can lower IT barriers to innovation.[74]
Despite the wide utilization of cloud computing, efficient sharing of large volumes of data in an untrusted cloud is still a challenge.
References
- ↑ Sun microsystem, p. 1
- ↑ Fabio Kon, p. 1
- ↑ Kobayashi et al. 2011, p. 1
- ↑ Angabini et al. 2011, p. 1
- ↑ Di Sano et al. 2012, p. 2
- ↑ Andrew & Maarten 2006, p. 492
- ↑ Andrew & Maarten 2006, p. 496
- ↑ Humbetov 2012, p. 2
- 1 2 3 Krzyzanowski 2012, p. 2
- ↑ Pavel Bžoch, p. 7
- ↑ Kai et al. 2013, p. 23
- 1 2 Hsiao et al. 2013, p. 2
- ↑ Hsiao et al. 2013, p. 952
- ↑ Ghemawat, Gobioff & Leung 2003, p. 1
- ↑ Ghemawat, Gobioff & Leung 2003, p. 8
- ↑ Hsiao et al. 2013, p. 953
- ↑ Di Sano et al. 2012, pp. 1–2
- ↑ Krzyzanowski 2012, p. 4
- ↑ Di Sano et al. 2012, p. 2
- ↑ Andrew & Maarten 2006, p. 497
- ↑ Humbetov 2012, p. 3
- ↑ Humbetov 2012, p. 5
- ↑ Andrew & Maarten 2006, p. 498
- ↑ Krzyzanowski 2012, p. 5
- ↑
- ↑ Fan-Hsun et al. 2012, p. 2
- ↑ http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Assumptions_and_Goals
- ↑ Azzedin 2013, p. 2
- 1 2 Adamov 2012, p. 2
- ↑ Yee & Thu Naing 2011, p. 122
- ↑ Soares et al. 2013, p. 158
- ↑ Perez, Nicolas. "How MapR improves our productivity and simplifies our design". Medium. Medium. Retrieved June 21, 2016.
- ↑ Woodie, Alex. "From Hadoop to Zeta: Inside MapR's Convergence Conversion". Datanami. Tabor Communications Inc. Retrieved June 21, 2016.
- ↑ Brennan, Bob. "Flash Memory Summit". youtube. Samsung. Retrieved June 21, 2016.
- ↑ Srivas, MC. "MapR File System". Hadoop Summit 2011. Hortonworks. Retrieved June 21, 2016.
- ↑ Dunning, Ted; Friedman, Ellen (January 2015). "Chapter 3: Understanding the MapR Distribution for Apache Hadoop". Real World Hadoop (First ed.). Sebastopol, CA: O'Reilly Media, Inc. pp. 23–28. ISBN 978-1-491-92395-5. Retrieved June 21, 2016.
- ↑ Weil et al. 2006, p. 307
- ↑ Maltzahn et al. 2010, p. 39
- ↑ Jacobi & Lingemann, p. 10
- ↑ Schwan Philip 2003, p. 401
- ↑ Jones, Koniges & Yates 2000, p. 1
- ↑ Upadhyaya et al. 2008, p. 400
- ↑ Upadhyaya et al. 2008, p. 403
- ↑ Upadhyaya et al. 2008, p. 401
- ↑ Upadhyaya et al. 2008, p. 402
- 1 2 Uppoor, Flouris & Bilas 2010, p. 1
- 1 2 Zhifeng & Yang 2013, p. 854
- ↑ Zhifeng & Yang 2013, pp. 845–846
- ↑ Yau & An 2010, p. 353
- ↑ Vecchiola, Pandey & Buyya 2009, p. 14
- ↑ Yau & An 2010, p. 352
- ↑ Miranda & Siani 2009
- ↑ Naehrig & Lauter 2013
- ↑ Zhifeng & Yang 2013, p. 5
- ↑ Juels & Oprea 2013, p. 4
- ↑ Bowers, Juels & Oprea 2009
- ↑ Juels & S. Kaliski 2007, p. 2
- ↑ Ateniese et al. Kissner
- ↑ Ateniese et al. 2008, pp. 5, 9
- ↑ Erway et al. 2009, p. 2
- 1 2 Bonvin, Papaioannou & Aberer 2009, p. 206
- ↑ Cuong et al. 2012, p. 5
- ↑ A., A. & P. 2011, p. 3
- ↑ Qian, D. & T. 2011, p. 3
- ↑ Vogels 2009, p. 2
- ↑ Bonvin, Papaioannou & Aberer 2009, p. 208
- 1 2 Carnegie et al. 2009, p. 1
- 1 2 Wang et al. 2012, p. 1
- ↑ Abu-Libdeh, Princehouse & Weatherspoon 2010, p. 2
- ↑ Wang et al. 2012, p. 9
- ↑ Lori M. Kaufman 2009, p. 2
- ↑ Angabini et al. 2011, p. 1
- ↑ Bonvin, Papaioannou & Aberer 2009, p. 3
- ↑ Marston et al. 2011, p. 3
Bibliography
- Andrew, S.Tanenbaum; Maarten, Van Steen (2006). Distributed systems principles and paradigms (PDF).
- Fabio Kon. "Distributed File Systems,The State of the Art and concept of Ph.D. Thesis".
- Pavel Bžoch. "Distributed File Systems Past, Present and Future A Distributed File System for 2006 (1996)" (PDF).
- Sun microsystem. "Distributed file systems – an overview" (PDF).
- Jacobi, Tim-Daniel; Lingemann, Jan. "Evaluation of Distributed File Systems" (PDF).
- Architecture, structure, and design:
- Zhang, Qi-fei; Pan, Xue-zeng; Shen, Yan; Li, Wen-juan (2012). "A Novel Scalable Architecture of Cloud Storage System for Small Files Based on P2P". 2012 IEEE International Conference on Cluster Computing Workshops. Coll. of Comput. Sci. & Technol., Zhejiang Univ., Hangzhou, China. p. 41. doi:10.1109/ClusterW.2012.27. ISBN 978-0-7695-4844-9. Lay summary.
- Azzedin, Farag (2013). "Towards a scalable HDFS architecture". 2013 International Conference on Collaboration Technologies and Systems (CTS). Information and Computer Science Department King Fahd University of Petroleum and Minerals. pp. 155–161. doi:10.1109/CTS.2013.6567222. ISBN 978-1-4673-6404-1. Lay summary.
- Krzyzanowski, Paul (2012). "Distributed File Systems" (PDF).
- Kobayashi, K; Mikami, S; Kimura, H; Tatebe, O (2011). The Gfarm File System on Compute Clouds. Parallel and Distributed Processing Workshops and Phd Forum (IPDPSW), 2011 IEEE International Symposium on. Grad. Sch. of Syst. & Inf. Eng., Univ. of Tsukuba, Tsukuba, Japan. doi:10.1109/IPDPS.2011.255.
- Humbetov, Shamil (2012). "Data-intensive computing with map-reduce and hadoop". 2012 6th International Conference on Application of Information and Communication Technologies (AICT). Department of Computer Engineering Qafqaz University Baku, Azerbaijan. pp. 1–5. doi:10.1109/ICAICT.2012.6398489. ISBN 978-1-4673-1740-5. Lay summary.
- Hsiao, Hung-Chang; Chung, Hsueh-Yi; Shen, Haiying; Chao, Yu-Chang (2013). National Cheng Kung University, Tainan. "Load Rebalancing for Distributed File Systems in Clouds". Parallel and Distributed Systems, IEEE Transactions on. 24 (5): 951–962. doi:10.1109/TPDS.2012.196. Lay summary.
- Kai, Fan; Dayang, Zhang; Hui, Li; Yintang, Yang (2013). "An Adaptive Feedback Load Balancing Algorithm in HDFS". 2013 5th International Conference on Intelligent Networking and Collaborative Systems. State Key Lab. of Integrated Service Networks, Xidian Univ., Xi'an, China. pp. 23–29. doi:10.1109/INCoS.2013.14. ISBN 978-0-7695-4988-0. Lay summary.
- Upadhyaya, B; Azimov, F; Doan, T.T; Choi, Eunmi; Kim, Sangbum; Kim, Pilsung (2008). "Distributed File System: Efficiency Experiments for Data Access and Communication". 2008 Fourth International Conference on Networked Computing and Advanced Information Management. Sch. of Bus. IT, Kookmin Univ., Seoul. pp. 400–405. doi:10.1109/NCM.2008.164. ISBN 978-0-7695-3322-3. Lay summary.
- Soares, Tiago S.; Dantas†, M.A.R; de Macedo, Douglas D.J.; Bauer, Michael A (2013). "A Data Management in a Private Cloud Storage Environment Utilizing High Performance Distributed File Systems". 2013 Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprises. nf. & Statistic Dept. (INE), Fed. Univ. of Santa Catarina (UFSC), Florianopolis, Brazil. pp. 158–163. doi:10.1109/WETICE.2013.12. ISBN 978-1-4799-0405-1. Lay summary.
- Adamov, Abzetdin (2012). "Distributed file system as a basis of data-intensive computing". 2012 6th International Conference on Application of Information and Communication Technologies (AICT). Comput. Eng. Dept., Qafqaz Univ., Baku, Azerbaijan. pp. 1–3. doi:10.1109/ICAICT.2012.6398484. ISBN 978-1-4673-1740-5. Lay summary.
- Schwan Philip (2003). Cluster File Systems, Inc.. "Lustre: Building a File System for 1,000-node Clusters" (PDF). Proceedings of the 2003 Linux Symposium: 400–407. Lay summary.
- Jones, Terry; Koniges, Alice; Yates, R. Kim (2000). Lawrence Livermore National Laboratory. "Performance of the IBM General Parallel File System" (PDF). Parallel and Distributed Processing Symposium, 2000. IPDPS 2000. Proceedings. 14th International. Lay summary.
- Weil, Sage A.; Brandt, Scott A.; Miller, Ethan L.; Long, Darrell D. E. (2006). "Ceph: A Scalable, High-Performance Distributed File System" (PDF). University of California, Santa Cruz.
- Maltzahn, Carlos; Molina-Estolano, Esteban; Khurana, Amandeep; Nelson, Alex J.; Brandt, Scott A.; Weil, Sage (2010). "Ceph as a scalable alternative to the Hadoop Distributed FileSystem" (PDF).
- S.A., Brandt; E.L., Miller; D.D.E., Long; Lan, Xue (2003). "Efficient metadata management in large distributed storage systems". 20th IEEE/11th NASA Goddard Conference on Mass Storage Systems and Technologies, 2003. (MSST 2003). Proceedings. Storage Syst. Res. Center, California Univ., Santa Cruz, CA, USA. pp. 290–298. doi:10.1109/MASS.2003.1194865. ISBN 0-7695-1914-8. Lay summary.
- Garth A., Gibson; Rodney, MVan Meter (November 2000). "Network attached storage architecture" (PDF). Communications of the ACM. 43 (11).
- Yee, Tin Tin; Thu Naing, Thinn (2011). "PC-Cluster based Storage System Architecture for Cloud Storage". The Smithsonian/NASA Astrophysics Data System. 1112: arXiv:1112.2025. arXiv:1112.2025
 . Bibcode:2011arXiv1112.2025T.
. Bibcode:2011arXiv1112.2025T. - Cho Cho, Khaing; Thinn Thu, Naing (2011). "The efficient data storage management system on cluster-based private cloud data center". 2011 IEEE International Conference on Cloud Computing and Intelligence Systems. pp. 235–239. doi:10.1109/CCIS.2011.6045066. ISBN 978-1-61284-203-5. Lay summary.
- S.A., Brandt; E.L., Miller; D.D.E., Long; Lan, Xue (2011). "A carrier-grade service-oriented file storage architecture for cloud computing". 2011 3rd Symposium on Web Society. PCN&CAD Center, Beijing Univ. of Posts & Telecommun., Beijing, China. pp. 16–20. doi:10.1109/SWS.2011.6101263. ISBN 978-1-4577-0211-2. Lay summary.
- Ghemawat, Sanjay; Gobioff, Howard; Leung, Shun-Tak (2003). "The Google file system". Proceedings of the nineteenth ACM symposium on Operating systems principles - SOSP '03. pp. 29–43. doi:10.1145/945445.945450. ISBN 1581137575. Lay summary.
- Security
- Vecchiola, C; Pandey, S; Buyya, R (2009). "High-Performance Cloud Computing: A View of Scientific Applications". 2009 10th International Symposium on Pervasive Systems, Algorithms, and Networks. Dept. of Comput. Sci. & Software Eng., Univ. of Melbourne, Melbourne, VIC, Australia. pp. 4–16. doi:10.1109/I-SPAN.2009.150. ISBN 978-1-4244-5403-7. Lay summary.
- Miranda, Mowbray; Siani, Pearson (2009). "A client-based privacy manager for cloud computing". Proceedings of the Fourth International ICST Conference on COMmunication System softWAre and middlewaRE - COMSWARE '09. p. 1. doi:10.1145/1621890.1621897. ISBN 9781605583532. Lay summary.
- Naehrig, Michael; Lauter, Kristin (2013). "Can homomorphic encryption be practical?". Proceedings of the 3rd ACM workshop on Cloud computing security workshop - CCSW '11. pp. 113–124. doi:10.1145/2046660.2046682. ISBN 9781450310048. Lay summary.
- Du, Hongtao; Li, Zhanhuai (2012). "PsFS: A high-throughput parallel file system for secure Cloud Storage system". 2012 International Conference on Measurement, Information and Control (MIC). 1. Comput. Coll., Northwestern Polytech. Univ., Xi'An, China. pp. 327–331. doi:10.1109/MIC.2012.6273264. ISBN 978-1-4577-1604-1. Lay summary.
- A.Brandt, Scott; L.Miller, Ethan; D.E.Long, Darrell; Xue, Lan (2003). Storage Systems Research Center University of California,Santa Cruz. "Efficient Metadata Management in Large Distributed Storage Systems" (PDF). 11th NASA Goddard Conference on Mass Storage Systems and Technologies, San Diego,CA.
- Lori M. Kaufman (2009). "Data Security in the World of Cloud Computing". Security & Privacy, IEEE. 7 (4): 161–64. doi:10.1109/MSP.2009.87. Lay summary.
- Bowers, Kevin; Juels, Ari; Oprea, Alina (2009). "HAIL: a high-availability and integrity layer for cloud storageComputing". Proceedings of the 16th ACM conference on Computer and communications security: 187–198. doi:10.1145/1653662.1653686. ISBN 9781605588940. Lay summary.
- Juels, Ari; Oprea, Alina (February 2013). "New approaches to security and availability for cloud data". Magazine Communications of the ACM CACM Homepage archive. 56 (2): 64–73. doi:10.1145/2408776.2408793. Lay summary.
- Zhang, Jing; Wu, Gongqing; Hu, Xuegang; Wu, Xindong (2012). "A Distributed Cache for Hadoop Distributed File System in Real-Time Cloud Services". 2012 ACM/IEEE 13th International Conference on Grid Computing. Dept. of Comput. Sci., Hefei Univ. of Technol., Hefei, China. pp. 12–21. doi:10.1109/Grid.2012.17. ISBN 978-1-4673-2901-9. Lay summary.
- A., Pan; J.P., Walters; V.S., Pai; D.-I.D., Kang; S.P., Crago (2012). "Integrating High Performance File Systems in a Cloud Computing Environment". 2012 SC Companion: High Performance Computing, Networking Storage and Analysis. Dept. of Electr. & Comput. Eng., Purdue Univ., West Lafayette, IN, USA. pp. 753–759. doi:10.1109/SC.Companion.2012.103. ISBN 978-0-7695-4956-9. Lay summary.
- Fan-Hsun, Tseng; Chi-Yuan, Chen; Li-Der, Chou; Han-Chieh, Chao (2012). "Implement a reliable and secure cloud distributed file system". 2012 International Symposium on Intelligent Signal Processing and Communications Systems. Dept. of Comput. Sci. & Inf. Eng., Nat. Central Univ., Taoyuan, Taiwan. pp. 227–232. doi:10.1109/ISPACS.2012.6473485. ISBN 978-1-4673-5082-2. Lay summary.
- Di Sano, M; Di Stefano, A; Morana, G; Zito, D (2012). "File System As-a-Service: Providing Transient and Consistent Views of Files to Cooperating Applications in Clouds". 2012 IEEE 21st International Workshop on Enabling Technologies: Infrastructure for Collaborative Enterprises. Dept. of Electr., Electron. & Comput. Eng., Univ. of Catania, Catania, Italy. pp. 173–178. doi:10.1109/WETICE.2012.104. ISBN 978-1-4673-1888-4. Lay summary.
- Zhifeng, Xiao; Yang, Xiao (2013). "Security and Privacy in Cloud Computing". Communications Surveys & Tutorials, IEEE. 15 (2): 843–859. doi:10.1109/SURV.2012.060912.00182. Lay summary.
- John B, Horrigan (2008). "Use of cloud computing applications and services" (PDF).
- Yau, Stephen; An, Ho (2010). "Confidentiality Protection in cloud computing systems". Int J Software Informatics: 351–365.
- Carnegie, Bin Fan; Tantisiriroj, Wittawat; Xiao, Lin; Gibson, Garth (2009). "Disk Reduce". DiskReduce: RAID for data-intensive scalable computing. pp. 6–10. doi:10.1145/1713072.1713075. ISBN 9781605588834. Lay summary.
- Wang, Jianzong; Gong, Weijiao; P., Varman; Xie, Changsheng (2012). "Reducing Storage Overhead with Small Write Bottleneck Avoiding in Cloud RAID System". 2012 ACM/IEEE 13th International Conference on Grid Computing. pp. 174–183. doi:10.1109/Grid.2012.29. ISBN 978-1-4673-2901-9. Lay summary.
- Abu-Libdeh, Hussam; Princehouse, Lonnie; Weatherspoon, Hakim (2010). "RACS: a case for cloud storage diversity". SoCC '10 Proceedings of the 1st ACM symposium on Cloud computing: 229–240. doi:10.1145/1807128.1807165. ISBN 9781450300360. Lay summary.
- Vogels, Werner (2009). "Eventually consistent". Communications of the ACM - Rural engineering development CACM. 52 (1): 40–44. doi:10.1145/1435417.1435432. Lay summary.
- Cuong, Pham; Cao, Phuong; Kalbarczyk, Z; Iyer, R.K (2012). "Toward a high availability cloud: Techniques and challenges". IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN 2012). pp. 1–6. doi:10.1109/DSNW.2012.6264687. ISBN 978-1-4673-2266-9. Lay summary.
- A., Undheim; A., Chilwan; P., Heegaard (2011). "Differentiated Availability in Cloud Computing SLAs". 2011 IEEE/ACM 12th International Conference on Grid Computing. pp. 129–136. doi:10.1109/Grid.2011.25. ISBN 978-1-4577-1904-2.
- Qian, Haiyang; D., Medhi; T., Trivedi (2011). "A hierarchical model to evaluate quality of experience of online services hosted by cloud computing". Communications of the ACM - Rural engineering development CACM. 52 (1): 105–112. doi:10.1109/INM.2011.5990680.
- Ateniese, Giuseppe; Burns, Randal; Curtmola, Reza; Herring, Joseph; Kissner, Lea; Peterson, Zachary; Song, Dawn (2007). "Provable data possession at untrusted stores". Proceedings of the 14th ACM conference on Computer and communications security - CCS '07. pp. 598–609. doi:10.1145/1315245.1315318. ISBN 9781595937032. Lay summary.
- Ateniese, Giuseppe; Di Pietro, Roberto; V. Mancini, Luigi; Tsudik, Gene (2008). "Scalable and efficient provable data possession". Proceedings of the 4th international conference on Security and privacy in communication networks - Secure Comm '08. p. 1. doi:10.1145/1460877.1460889. ISBN 9781605582412. Lay summary.
- Erway, Chris; Küpçü, Alptekin; Tamassia, Roberto; Papamanthou, Charalampos (2009). "Dynamic provable data possession". Proceedings of the 16th ACM conference on Computer and communications security - CCS '09. pp. 213–222. doi:10.1145/1653662.1653688. ISBN 9781605588940. Lay summary.
- Juels, Ari; S. Kaliski, Burton (2007). "Pors: proofs of retrievability for large files". Proceedings of the 14th ACM conference on Computer and communications: 584–597. doi:10.1145/1315245.1315317. ISBN 9781595937032. Lay summary.
- Bonvin, Nicolas; Papaioannou, Thanasis; Aberer, Karl (2009). "A self-organized, fault-tolerant and scalable replication scheme for cloud storage". Proceedings of the 1st ACM symposium on Cloud computing - SoCC '10. pp. 205–216. doi:10.1145/1807128.1807162. ISBN 9781450300360. Lay summary.
- Tim, Kraska; Martin, Hentschel; Gustavo, Alonso; Donald, Kossma (2009). "Consistency rationing in the cloud: pay only when it matters" (PDF). Proceedings of the VLDB Endowment VLDB Endowment Homepage archive. 2 (1): 253–264. doi:10.1145/1690000/1687657 (inactive 2016-07-11). Lay summary.
- Daniel, J. Abadi (2009). "Data Management in the Cloud: Limitations and Opportunities" (PDF). IEEE. Lay summary.
- Ari, Juels; S., Burton; Jr, Kaliski (2007). "Pors: proofs of retrievability for large files". Communications of the ACM CACM. 56 (2): 584–597. doi:10.1145/1315245.1315317. Lay summary.
- Ari, Ateniese; Randal, Burns; Johns, Reza; Curtmola, Joseph; Herring, Burton; Lea, Kissner; Zachary, Peterson; Dawn, Song (2007). "Provable data possession at untrusted stores". CCS '07 Proceedings of the 14th ACM conference on Computer and communications security. pp. 598–609. doi:10.1145/1315245.1315318. ISBN 9781595937032. Lay summary.
- Synchronization
- Uppoor, S; Flouris, M.D; Bilas, A (2010). "Cloud-based synchronization of distributed file system hierarchies". 2010 IEEE International Conference on Cluster Computing Workshops and Posters (CLUSTER WORKSHOPS). Inst. of Comput. Sci. (ICS), Found. for Res. & Technol. - Hellas (FORTH), Heraklion, Greece. pp. 1–4. doi:10.1109/CLUSTERWKSP.2010.5613087. ISBN 978-1-4244-8395-2. Lay summary.
- Economic aspects
- Lori M., Kaufman (2009). "Data Security in the World of Cloud Computing". Security & Privacy, IEEE. 7 (4): 161–64. doi:10.1109/MSP.2009.87. Lay summary.
- Marston, Sean; Lia, Zhi; Bandyopadhyaya, Subhajyoti; Zhanga, Juheng; Ghalsasi, Anand (2011). Cloud computing — The business perspective. Decision Support Systems Volume 51, Issue 1,. pp. 176–189. doi:10.1016/j.dss.2010.12.006.
- Angabini, A; Yazdani, N; Mundt, T; Hassani, F (2011). "Suitability of Cloud Computing for Scientific Data Analyzing Applications; an Empirical Study". 2011 International Conference on P2P, Parallel, Grid, Cloud and Internet Computing. Sch. of Electr. & Comput. Eng., Univ. of Tehran, Tehran, Iran. pp. 193–199. doi:10.1109/3PGCIC.2011.37. ISBN 978-1-4577-1448-1. Lay summary.