Distributed memory
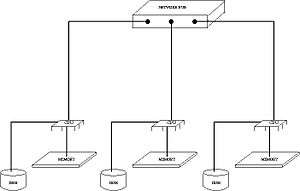
In computer science, distributed memory refers to a multiprocessor computer system in which each processor has its own private memory. Computational tasks can only operate on local data, and if remote data is required, the computational task must communicate with one or more remote processors. In contrast, a shared memory multiprocessor offers a single memory space used by all processors. Processors do not have to be aware where data resides, except that there may be performance penalties, and that race conditions are to be avoided.
Architecture
In a distributed memory system there is typically a processor, a memory, and some form of interconnection that allows programs on each processor to interact with each other. The interconnect can be organised with point to point links or separate hardware can provide a switching network. The network topology is a key factor in determining how the multiprocessor machine scales. The links between nodes can be implemented using some standard network protocol (for example Ethernet), using bespoke network links (used in for example the Transputer), or using dual-ported memories.
Programming distributed memory machines
The key issue in programming distributed memory systems is how to distribute the data over the memories. Depending on the problem solved, the data can be distributed statically, or it can be moved through the nodes. Data can be moved on demand, or data can be pushed to the new nodes in advance.
As an example, if a problem can be described as a pipeline where data x is processed subsequently through functions f, g, h, etc. (the result is h(g(f(x)))), then this can be expressed as a distributed memory problem where the data is transmitted first to the node that performs f that passes the result onto the second node that computes g, and finally to the third node that computes h. This is also known as systolic computation.
Data can be kept statically in nodes if most computations happen locally, and only changes on edges have to be reported to other nodes. An example of this is simulation where data is modeled using a grid, and each node simulates a small part of the larger grid. On every iteration, nodes inform all neighboring nodes of the new edge data.
Distributed shared memory
Similarly, in distributed shared memory each node of a cluster has access to a large shared memory in addition to each node's limited non-shared private memory.
Shared memory vs. distributed memory vs. distributed shared memory
- The advantage of (distributed) shared memory is that it offers a unified address space in which all data can be found.
- The advantage of distributed memory is that it excludes race conditions, and that it forces the programmer to think about data distribution.
- The advantage of distributed (shared) memory is that it is easier to design a machine that scales with the algorithm
Distributed shared memory hides the mechanism of communication, it does not hide the latency of communication.
See also
| General | |
|---|---|
| Levels | |
| Multithreading | |
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |