Extended Boolean model
The Extended Boolean model was described in a Communications of the ACM article appearing in 1983, by Gerard Salton, Edward A. Fox, and Harry Wu. The goal of the Extended Boolean model is to overcome the drawbacks of the Boolean model that has been used in information retrieval. The Boolean model doesn't consider term weights in queries, and the result set of a Boolean query is often either too small or too big. The idea of the extended model is to make use of partial matching and term weights as in the vector space model. It combines the characteristics of the Vector Space Model with the properties of Boolean algebra and ranks the similarity between queries and documents. This way a document may be somewhat relevant if it matches some of the queried terms and will be returned as a result, whereas in the Standard Boolean model it wasn't.[1]
Thus, the extended Boolean model can be considered as a generalization of both the Boolean and vector space models; those two are special cases if suitable settings and definitions are employed. Further, research has shown effectiveness improves relative to that for Boolean query processing. Other research has shown that relevance feedback and query expansion can be integrated with extended Boolean query processing.
Definitions
In the Extended Boolean model, a document is represented as a vector (similarly to in the vector model). Each i dimension corresponds to a separate term associated with the document.
The weight of term Kx associated with document dj is measured by its normalized Term frequency and can be defined as:

where Idfx is inverse document frequency.
The weight vector associated with document dj can be represented as:
![{\displaystyle \mathbf {v} _{d_{j}}=[w_{1,j},w_{2,j},\ldots ,w_{i,j}]}](../I/m/7630d41a2858849a4a1998c1a7bf46c90a18d7cc.svg)
The 2 Dimensions Example
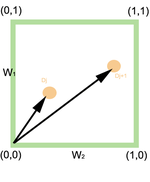
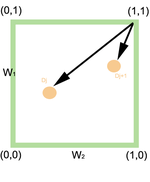
Considering the space composed of two terms Kx and Ky only, the corresponding term weights are w1 and w2.[2] Thus, for query qor = (Kx ∨ Ky), we can calculate the similarity with the following formula:

For query qand = (Kx ∧ Ky), we can use:

Generalizing the idea and P-norms
We can generalize the previous 2D extended Boolean model example to higher t-dimensional space using Euclidean distances.
This can be done using P-norms which extends the notion of distance to include p-distances, where 1 ≤ p ≤ ∞ is a new parameter.[3]
- A generalized conjunctive query is given by:

- The similarity of and can be defined as:


:
![{\displaystyle sim(q_{or},d_{j})={\sqrt[{p}]{\frac {w_{1}^{p}+w_{2}^{p}+....+w_{t}^{p}}{t}}}}](../I/m/4ee6fd28a0b708483aa6ff23a382886234751498.svg)
- A generalized disjunctive query is given by:

- The similarity of and can be defined as:

![{\displaystyle sim(q_{and},d_{j})=1-{\sqrt[{p}]{\frac {(1-w_{1})^{p}+(1-w_{2})^{p}+....+(1-w_{t})^{p}}{t}}}}](../I/m/e8a46594acad810a7ec2e9e62a712b694fb18916.svg)
Examples
Consider the query q = (K1 ∧ K2) ∨ K3. The similarity between query q and document d can be computed using the formula:
![{\displaystyle sim(q,d)={\sqrt[{p}]{\frac {(1-{\sqrt[{p}]{({\frac {(1-w_{1})^{p}+(1-w_{2})^{p}}{2}}}}))^{p}+w_{3}^{p}}{2}}}}](../I/m/74b3d2b11ee65d16df85d7d45087259d37a10215.svg)
Improvements over the Standard Boolean Model
Lee and Fox[4] compared the Standard and Extended Boolean models with three test collections, CISI, CACM and INSPEC.
Using P-norms they obtained an average precision improvement of 79%, 106% and 210% over the Standard model, for the CISI, CACM and INSPEC collections, respectively.
The P-norm model is computationally expensive because of the number of exponentiation operations that it requires but it achieves much better results than the Standard model and even Fuzzy retrieval techniques. The Standard Boolean model is still the most efficient.
Further reading
- Adaptive Feedback Methods in an Extended Boolean Model by Dr.Jongpill Choi
- Interpolation of the extended Boolean retrieval model
- Fox, E.; Betrabet, S.; Koushik, M.; Lee, W. (1992), Information Retrieval: Algorithms and Data structures; Extended Boolean model, Prentice-Hall, Inc.
- Skorkovská, Lucie; Ircing, Pavel (2009), Experiments with Automatic Query Formulation in the Extended Boolean Model, Springer Berlin / Heidelberg
See also
References
- ↑ Salton, Gerard; Fox, Edward A.; Wu, Harry (1983), Extended Boolean information retrieval, Communications of the ACM, Volume 26, Issue 11
- ↑ Lusheng Wang
- ↑ Garcia, Dr. E., The Extended Boolean Model - Weighted Queries: Term Weights, p-Norm Queries and Multiconcept Types. Boolean OR Extended? AND that is the Query
- ↑ Lee, W. C.; Fox, E. A. (1988), Experimental Comparison of Schemes for Interpreting Boolean Queries (PDF)