Grammatical Framework
Grammatical Framework (GF) is a programming language for writing grammars of natural languages. GF is capable of parsing and generating texts in several languages simultaneously while working from a language-independent representation of meaning. Grammars written in GF can be compiled into different formats including JavaScript and Java and can be reused as software components. A companion to GF is the GF Resource Grammar Library, a reusable library for dealing with the morphology and syntax of a growing number of natural languages.
Both GF itself and the GF Resource Grammar Library are open-source. Typologically, GF is a functional programming language. Mathematically, it is a type-theoretic formal system (a logical framework to be precise) based on Martin-Löf's intuitionistic type theory, with additional judgments tailored specifically to the domain of linguistics.
Language features
- a static type system, to detect potential programming errors
- functional programming for powerful abstractions
- support for writing libraries, to be used on other grammars
- tools for Information extraction, to convert linguistic resources into GF[1]
Tutorial
This example is taken from the LREC 2010 tutorial
Goal: write a multilingual grammar for expressing statements about John and Mary loving each other.
Abstract & concrete modules
In GF, grammars are divided to two module types:
- an abstract module, containing judgement forms cat and fun.
- cat or category declarations list categories i.e. all the possible types of trees there can be.
- fun or function declarations state functions and their types, these must be implemented by concrete modules (see below).
- one or more concrete modules, containing judgement forms lincat and lin.
- lincat or linearization type definitions, says what type of objects linearization produces for each category listed in cat.
- lin or linearization rules implement functions declared in fun. They say how trees are linearized.
Consider the following:
Abstract syntax
abstract Zero = {
cat
S ; NP ; VP ; V2 ;
fun
Pred : NP -> VP -> S ;
Compl : V2 -> NP -> VP ;
John, Mary : NP ;
Love : V2 ;
}
Concrete syntax: English
concrete ZeroEng of Zero = {
lincat
S, NP, VP, V2 = Str ;
lin
Pred np vp = np ++ vp ;
Compl v2 np = v2 ++ np ;
John = "John" ;
Mary = "Mary" ;
Love = "loves" ;
}
Notice: Str (token list or "string") as the only linearization type.
Making a grammar multilingual
A single abstract syntax may be applied to many concrete syntaxes, in our case one for each new natural language we wish to add. The same system of trees can be given:
- different words
- different word orders
- different linearization types
Concrete syntax: French
concrete ZeroFre of Zero = {
lincat
S, NP, VP, V2 = Str ;
lin
Pred np vp = np ++ vp ;
Compl v2 np = v2 ++ np ;
John = "Jean" ;
Mary = "Marie" ;
Love = "aime" ;
}
Translation and multilingual generation
We can now use our grammar to translate phrases between French and English. The following commands can be executed in the GF interactive shell.
Import many grammars with the same abstract syntax
> import ZeroEng.gf ZeroFre.gf
Languages: ZeroEng ZeroFre
Translation: pipe linearization to parsing
> parse -lang=Eng "John loves Mary" | linearize -lang=Fre
Jean aime Marie
Multilingual generation: linearize into all languages
> generate_random | linearize -treebank
Zero: Pred Mary (Compl Love Mary)
ZeroEng: Mary loves Mary
ZeroFre: Marie aime Marie
Parameters, tables
Latin has cases: nominative for subject, accusative for object.
- Ioannes Mariam amat "John-Nom loves Mary-Acc"
- Maria Ioannem amat "Mary-Nom loves John-Acc"
We use a parameter type for case (just 2 of Latin's 6 cases). The linearization type of NP is a table type: from Case to Str. The linearization of John is an inflection table. When using an NP, we select (!) the appropriate case from the table.
Concrete syntax: Latin
concrete ZeroLat of Zero = {
lincat
S, VP, V2 = Str ;
NP = Case => Str ;
lin
Pred np vp = np ! Nom ++ vp ;
Compl v2 np = np ! Acc ++ v2 ;
John = table {Nom => "Ioannes" ; Acc => "Ioannem"} ;
Mary = table {Nom => "Maria" ; Acc => "Mariam"} ;
Love = "amat" ;
param
Case = Nom | Acc ;
}
Discontinuous constituents, records
In Dutch, the verb heeft lief is a discontinuous constituent. The linearization type of V2 is a record type with two fields. The linearization of Love is a record. The values of fields are picked by projection (.)
Concrete syntax: Dutch
concrete ZeroDut of Zero = {
lincat
S, NP, VP = Str ;
V2 = {v : Str ; p : Str} ;
lin
Pred np vp = np ++ vp ;
Compl v2 np = v2.v ++ np ++ v2.p ;
John = "Jan" ;
Mary = "Marie" ;
Love = {v = "heeft" ; p = "lief"} ;
}
Variable and inherent features, agreement, Unicode support
For Hebrew, NP has gender as its inherent feature – a field in the record. VP has gender as its variable feature – an argument of a table. In predication, the VP receives the gender of the NP.
Concrete syntax: Hebrew
concrete ZeroHeb of Zero = {
flags coding=utf8 ;
lincat
S = Str ;
NP = {s : Str ; g : Gender} ;
VP, V2 = Gender => Str ;
lin
Pred np vp = np.s ++ vp ! np.g ;
Compl v2 np = table {g => v2 ! g ++ "את" ++ np.s} ;
John = {s = "ג׳ון" ; g = Masc} ;
Mary = {s = "מרי" ; g = Fem} ;
Love = table {Masc => "אוהב" ; Fem => "אוהבת"} ;
param
Gender = Masc | Fem ;
}
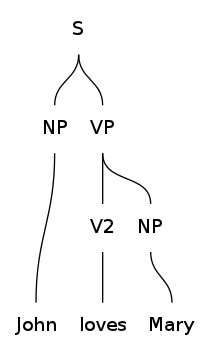
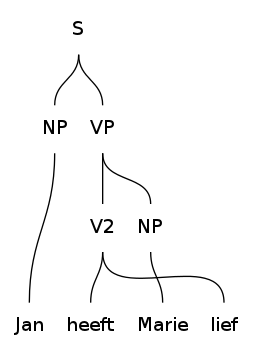
Visualizing parse trees
GF has inbuilt functions which can be used for visualizing parse trees and word alignments.
The following commands will generate parse trees for the given phrases and open the produced PNG image using the system's eog command.
> parse -lang=Eng "John loves Mary" | visualize_parse -view="eog"
> parse -lang=Dut "Jan heeft Marie lief" | visualize_parse -view="eog"
 |
 |
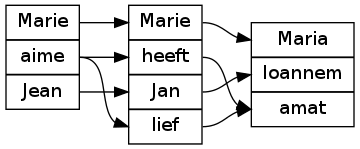
Generating word alignment
- In languages L1 and L2: link every word with its smallest spanning subtree.
- Delete the intervening tree, combining links directly from L1 to L2.
In general, this gives phrase alignment. Links can be crossing, phrases can be discontinuous. The align_words command follows a similar syntax:
> parse -lang=Fre "Marie aime Jean" | align_words -lang=Fre,Dut,Lat -view="eog"
Resource Grammar Library
In natural language applications, libraries are a way to cope with thousands of details involved in syntax, lexicon, and inflection. The GF Resource Grammar Library is the standard library for Grammatical Framework. It covers the morphology and basic syntax of 20 languages:
Amharic (partial), Arabic (partial), Bulgarian, Catalan, Danish, Dutch, English, Finnish, French, German, Hindi (fragments), Interlingua, Italian, Latin (fragments), Nepali, Norwegian bokmål, Persian, Polish, Punjabi, Romanian, Russian, Spanish, Swedish, Thai (fragments), Turkish (fragments), Urdu
A full API documentation of the library can be found at the RGL Synopsis page. The RGL status document gives the languages currently available in the GF Resource Grammar Library, including their maturity.
Uses of GF
GF was first created in 1998 at Xerox Research Centre Europe, Grenoble, in the project Multilingual Document Authoring. At Xerox, it was used for prototypes including a restaurant phrase book, a database query system, a formalization of an alarm system instructions with translations to 5 languages, and an authoring system for medical drug descriptions.
Later projects using GF and involving third parties include:
- MOLTO: multilingual online translation
- SALDO: Swedish morphological dictionary based on rules developed for GF and Functional Morphology
- WebAlt: multilingual generation of mathematical exercises (commercial project)
- TALK: multilingual and multimodal spoken dialogue systems
Academically, GF has been used in four PhD theses and resulted in around fifty scientific publications (see GF publication list).
Community
Developer Mailing List
There is an active group for developers and users of GF alike, located at https://groups.google.com/group/gf-dev
Summer Schools
2013 – Scaling Up Grammatical Resources (Lake Chiemsee, Germany)
The third GF Summer school, was held on Frauenchiemsee island in Bavaria, Germany with the special theme "Scaling up Grammar Resources". This summer school focused on extending the existing resource grammars with the ultimate goal of dealing with any text in the supported languages. Lexicon extension is an obvious part of this work, but also new grammatical constructions were also of interest. There was a special interest in porting resources from other open-source approaches, such as WordNets and Apertium, and reciprocally making GF resources easily reusable in other approaches.
2011 – Frontiers of Multilingual Technologies (Barcelona, Spain)
The second GF Summer school, subtitled Frontiers of Multilingual Technologies was held in 2011 in Barcelona, Spain. It was sponsored by CLT, the Centre for Language Technology of the University of Gothenburg, and by UPC, Universitat Politècnica de Catalunya. The School addressed new languages and also promoted ongoing work in those languages which are already under construction. Missing EU languages were especially encouraged.
The school began with a 2-day GF tutorial, serving those interested in getting an introduction to GF or an overview of on-going work.
All results of the summer school are available as open-source software released under the LGPL license.
2009 – GF Summer School (Gothenburg, Sweden)

The first GF summer school was held in 2009 in Gothenburg, Sweden. It was a collaborative effort to create grammars of new languages in Grammatical Framework, GF. These grammars were added to the Resource Grammar Library, which previously had 12 languages. Around 10 new languages are already under construction, and the School aimed to address 23 new languages. All results of the Summer School were made available as open-source software released under the LGPL license.
The summer school was organized by the Language Technology Group at the Department of Computer Science and Engineering. The group is a part of the Centre of Language Technology, a focus research area of the University of Gothenburg.
The code created by the school participants is made accessible in the GF darcs repository, subdirectory contrib/summerschool.
External links
References
- Ranta, Aarne (2004), "Grammatical Framework: A Type-Theoretical Grammar Formalism", Journal of Functional Programming, 14 (2): 145–189, doi:10.1017/s0956796803004738