Halton sequence

In statistics, Halton sequences are sequences used to generate points in space for numerical methods such as Monte Carlo simulations. Although these sequences are deterministic, they are of low discrepancy, that is, appear to be random for many purposes. They were first introduced in 1960 and are an example of a quasi-random number sequence. They generalise the one-dimensional van der Corput sequences, consult that article for a precise definition.
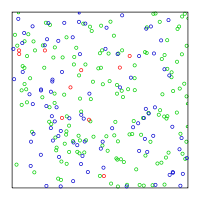
Example of Halton sequence used to generate points in (0, 1) × (0, 1) in R2
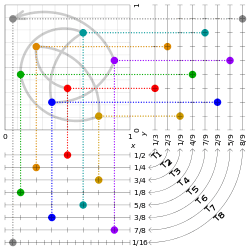
The Halton sequence is constructed according to a deterministic method that uses coprime numbers as its bases. As a simple example, let's take one dimension of the Halton sequence to be based on 2 and the other on 3. To generate the sequence for 2, we start by dividing the interval (0,1) in half, then in fourths, eighths, etc., which generates
- 1⁄2, 1⁄4, 3⁄4, 1⁄8, 5⁄8, 3⁄8, 7⁄8, 1⁄16, 9⁄16,...
Equivalently, the nth number of this sequence is the number n written in binary representation, inversed, and written after the decimal point. This is true for any base. As an example, to find the sixth element of the above sequence, we'd write 6 = 1*22 + 1*21 + 0*20 = 1102, which can be inverted and placed after the decimal point to give 0.0112 = 0*2-1 + 1*2-2 + 1*2-3 = 3⁄8. So the sequence above is the same as
- 0.12, 0.012, 0.112, 0.0012, 0.1012, 0.0112, 0.1112, 0.00012, 0.10012,...
To generate the sequence for 3, we divide the interval (0,1) in thirds, then ninths, twenty-sevenths, etc., which generates
- 1⁄3, 2⁄3, 1⁄9, 4⁄9, 7⁄9, 2⁄9, 5⁄9, 8⁄9, 1⁄27,...
When we pair them up, we get a sequence of points in a unit square:
- ( 1⁄2, 1⁄3), ( 1⁄4, 2⁄3), ( 3⁄4, 1⁄9), ( 1⁄8, 4⁄9), ( 5⁄8, 7⁄9), ( 3⁄8, 2⁄9), ( 7⁄8, 5⁄9), ( 1⁄16, 8⁄9), ( 9⁄16, 1⁄27).
Even though standard Halton sequences perform very well in low dimensions, correlation problems have been noted between sequences generated from higher primes. For example, if we started with the primes 17 and 19, the first 16 pairs of points: ( 1⁄17, 1⁄19), ( 2⁄17, 2⁄19), ( 3⁄17, 3⁄19) ... ( 16⁄17, 16⁄19) have perfect linear correlation. To avoid this, it is common to drop the first 20 entries, or some other predetermined number depending on the primes chosen. In order to deal with this problem, various other methods have been proposed; one of the most prominent solutions is the scrambled Halton sequence, which uses permutations of the coefficients used in the construction of the standard sequence. Another solution is using leaped Halton, just skipping points. If you use e.g. only each 409th point (also other prime numbers not used in the Halton core sequence are possible), then you can achieve significant improvements.
Implementation in pseudocode
FUNCTION (index, base)
BEGIN
result = 0;
f = 1;
i = index;
WHILE (i > 0)
BEGIN
f = f / base;
result = result + f * (i % base);
i = FLOOR(i / base);
END
RETURN result;
END
See also
References
- Kuipers, L.; Niederreiter, H. (2005), Uniform distribution of sequences, Dover Publications, p. 129, ISBN 0-486-45019-8
- Niederreiter, Harald (1992), Random number generation and quasi-Monte Carlo methods, SIAM, p. 29, ISBN 0-89871-295-5.
- Halton, J. (1964), Algorithm 247: Radical-inverse quasi-random point sequence, ACM, p. 701, doi:10.1145/355588.365104.