Presto (SQL query engine)
Presto is an Apache-licensed, open source SQL query engine optimized for high-speed interactive analytics at scale.
Description
Presto is an open source distributed ANSI SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes. Presto was designed and written from the ground up for interactive analytics while scaling to the size of organizations like Facebook.
Facebook commenced development efforts on Presto in 2012, and was later joined by other significant Presto users including Netflix, Airbnb and Groupon. In June 2015, data-warehousing leader Teradata joined the Presto community, pledging a roadmap of 100% open source features and offering enterprise support for Presto users.
Major Users
Facebook - Facebook uses Presto for interactive queries against several internal data stores, including their 300 PB Hadoop data warehouse
Netflix – Netflix handles a 25 PB data warehouse on S3 and uses Presto for its ad hoc interactive use cases
Airbnb – Airbnb is a significant contributor to the Presto community and uses Presto as the default query engine for its 1.5 PB data store. Airpal, Airbnb's open source web-based query execution tool, leverages Presto for data analysis, and has been used by more than one third of its employees.
Architecture
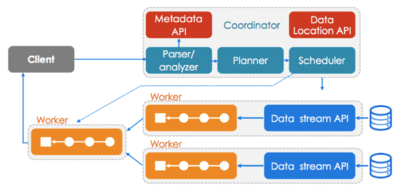
Presto’s architecture is very similar to the classic MPP DBMS architecture. It can be visualized as one coordinator node working in sync with multiple worker nodes. Clients submit SQL statements that get parsed and planned following which parallel tasks are scheduled to workers. Workers jointly process rows from the data sources and produce results that are returned to the client.
Presto query execution is extremely fast because of in-memory processing. Intermediate data is pipelined across nodes in the MPP fashion. As a result of CPU optimizations, vectorized operations and bytecode generation, this translates to highly interactive query performance.
Features
ANSI SQL Support
Presto offers extensive ANSI SQL support including:
- Standard SQL data types in addition to JSON, ARRAY, MAP and ROW
- Windowing functions
- Statistical and approximate aggregate functions
- UNNEST and TABLESAMPLE
Push down capabilities
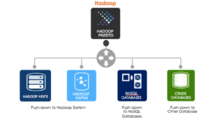
Presto allows querying data where it lives, including HDFS, Cassandra, relational databases and even proprietary data stores. A single Presto query can combine data from multiple sources, allowing for analytics across the enterprise ecosystem. Presto is targeted at analysts who expect response times ranging from sub-second to minutes.
Presto currently offers connectors to data sources including Hadoop HDFS, MySQL, Kafka, Cassandra, PostgreSQL and Redis. Many more connectors can be found on GitHub. Connectors allow JOIN operations across data in different sources, for example MySQL and HDFS. Connectors to additional data sources will continue to be released over time by major Presto contributors including Teradata.
Distro-agnostic
Several similar tools offer highly Hadoop distribution specific platforms. As a result, users tend to get locked into distribution specific solution stacks offered. Presto allows maintaining leverage among distributions like Hortonworks and Cloudera while allowing portability among them. BI tools supported by Presto therefore don't depend on the underlying Hadoop distributions.
References
- "Presto |Distributed SQL Query Engine for Big Data." Presto | Distributed SQL Query Engine for Big Data. Facebook. Web. 6 Oct. 2015.
- "Presto." SQL Engine for Hadoop & More. Teradata. Web. 6 Oct. 2015.
External links
- Facebook Presto website
- Teradata Presto commercial web site
- Airbnb Airpal blog release
- Netflix presto release