Sector/Sphere
|
Logo | |
| Developer(s) | The Sector Alliance |
|---|---|
| Stable release |
2.8
/ October 8, 2012 |
| Development status | Active |
| Written in | C++ |
| Operating system | Linux / Windows |
| Type | Distributed File System |
| License | Apache License 2.0 |
| Website | http://sector.sourceforge.net/ |
Sector/Sphere is an open source software suite for high-performance distributed data storage and processing. It can be broadly compared to Google's GFS/MapReduce stack. Sector is a distributed file system targeting data storage over a large number of commodity computers. Sphere is the programming framework that supports massive in-storage parallel data processing for data stored in Sector. Additionally, Sector/Sphere is unique in its ability to operate in a wide area network (WAN) setting.
The system was created by Dr. Yunhong Gu (the author of UDT) in 2006 and it is now maintained by a group of open source developers.
Architecture
Sector/Sphere consists of four components. The security server maintains the system security policies such as user accounts and the IP access control list. One or more master servers control operations of the overall system in addition to responding to various user requests. The slave nodes store the data files and process them upon request. The clients are the users' computers from which system access and data processing requests are issued. Also, Sector/Sphere is written in C++ and is claimed to achieve with its architecture a two to four times better performance than the competitor Hadoop which is written in Java,[1] a statement supported by an Aster Data Systems benchmark[2] and the winning of the "bandwidth challenge" of the Supercomputing Conference 2006,[3] 2008,[4] and 2009.[5]
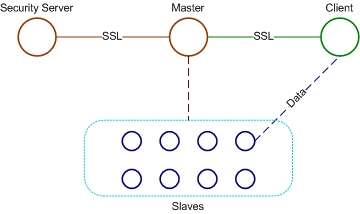
Sector Distributed File System
Sector is a user space file system which relies on the local/native file system of each node for storing uploaded files. Sector provides file system-level fault tolerance by replication, thus it does not require hardware fault tolerance such as RAID, which is usually very expensive.
Sector does not split user files into blocks; instead, a user file is stored intact on the local file system of one or more slave nodes. This means that Sector has a file size limitation that is application specific. The advantages, however, are that the Sector file system is very simple, and it leads to better performance in Sphere parallel data processing due to reduced data transfer between nodes. It also allows uploaded data to be accessible from outside the Sector system.
Sector provides many unique features compared to traditional file systems. Sector is topology aware. Users can define rules on how files are located and replicated in the system, according to network topology. For example, data from a certain user can be located on a specific cluster and will not be replicated to other racks. For another example, some files can have more replicas than others. Such rules can be applied at per-file level.
The topology awareness and the use of UDT as data transfer protocol allows Sector to support high performance data IO across geographically distributed locations, while most file systems can only be deployed within a local area network. For this reason, Sector is often deployed as a content distribution network for very large datasets.
Sector integrates data storage and processing into one system. Every storage node can also be used to process the data, thus it can support massive in-storage parallel data processing (see Sphere). Sector is application aware, meaning that it can provide data location information to applications and also allow applications to specify data location, whenever necessary.
As a simple example of the benefits of Sphere, Sector can return the results from such commands as "grep" and "md5sum" without reading the data out of the file system. Moreover, it can compute the results of multiple files in parallel.
The Sector client provides an API for application development which allows user applications to interact directly with Sector. The software also comes prepackaged with a set of command-line tools for accessing the file system. Finally, Sector supports the FUSE interface; presenting a mountable file system that is accessible via standard command-line tools.
Sphere Parallel Data Processing Engine
Sphere is a parallel data processing engine integrated in Sector and it can be used to process data stored in Sector in parallel. It can broadly compared to MapReduce, but it uses generic User Defined Functions (UDFs) instead of the map and reduce functions. A UDF can be either a map function or a reduce function, or even others.
Benefiting from the underlying Sector file system and the flexibility of the UDF model, Sphere can manipulate the locality of both input data and output data, thus it can effectively supports multiple input datasets, combinative and iterative operations, and even legacy application executable.
Because Sector does not split user files, Sphere can simply wrap up many existing applications that accepts files or directories as input, without rewriting them. Thus it can provide greater compatibility to legacy applications.
See also
- Pentaho - Open source data integration (Kettle), analytics, reporting, visualization and predictive analytics directly from Hadoop nodes
- Nutch - An effort to build an open source search engine based on Lucene and Hadoop, also created by Doug Cutting
- Datameer Analytics Solution (DAS) - data source integration, storage, analytics engine and visualization
- Apache Accumulo - Secure Big Table
- HBase - BigTable-model database
- Hypertable - HBase alternative
- MapReduce - Hadoop's fundamental data filtering algorithm
- Apache Mahout - Machine Learning algorithms implemented on Hadoop
- Apache Cassandra - A column-oriented database that supports access from Hadoop
- HPCC - LexisNexis Risk Solutions High Performance Computing Cluster
- Cloud computing
- Big data
- Data Intensive Computing
Literature
- Yunhong Gu, Robert Grossman, Sector and Sphere: The Design and Implementation of a High Performance Data Cloud, Theme Issue of the Philosophical Transactions of the Royal Society A: Crossing Boundaries: Computational Science, E-Science and Global E-Infrastructure, 28 June 2009 vol. 367 no. 1897 2429-2445.
References
- ↑ Sector vs. Hadoop - A Brief Comparison Between the Two Systems
- ↑ Sector/ Sphere – Faster than Hadoop/Mapreduce at Terasort September 26, 2010 Ajay Ohri
- ↑ NCDM Wins Bandwidth Challenge at SC06, HPCWire, November 24, 2006
- ↑ UIC Groups Win Bandwidth Challenge Award, HPCWire, November 20, 2008
- ↑ Open Cloud Testbed Wins Bandwidth Challenge at SC09, December 8, 2009