SimRank
SimRank is a general similarity measure, based on a simple and intuitive graph-theoretic model. SimRank is applicable in any domain with object-to-object relationships, that measures similarity of the structural context in which objects occur, based on their relationships with other objects. Effectively, SimRank is a measure that says "two objects are considered to be similar if they are referenced by similar objects." Although SimRank is widely adopted, it may output unreasonable similarity scores which are influenced by different factors, and can be solved in several ways, such as introducing an evidence weight factor,[1] inserting additional terms that are neglected by SimRank[2] or using PageRank-based alternatives.[3]
Introduction
Many applications require a measure of "similarity" between objects. One obvious example is the "find-similar-document" query, on traditional text corpora or the World-Wide Web. More generally, a similarity measure can be used to cluster objects, such as for collaborative filtering in a recommender system, in which “similar” users and items are grouped based on the users’ preferences.
Various aspects of objects can be used to determine similarity, usually depending on the domain and the appropriate definition of similarity for that domain. In a document corpus, matching text may be used, and for collaborative filtering, similar users may be identified by common preferences. SimRank is a general approach that exploits the object-to-object relationships found in many domains of interest. On the Web, for example, two pages are related if there are hyperlinks between them. A similar approach can be applied to scientific papers and their citations, or to any other document corpus with cross-reference information. In the case of recommender systems, a user’s preference for an item constitutes a relationship between the user and the item. Such domains are naturally modeled as graphs, with nodes representing objects and edges representing relationships.
The intuition behind the SimRank algorithm is that, in many domains, similar objects are referenced by similar objects.
More precisely, objects 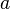 and
and 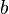 are considered to be similar if they are pointed from objects
are considered to be similar if they are pointed from objects  and
and 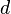 , respectively, and and are themselves similar.
The base case is that objects are maximally similar to themselves
.[4]
, respectively, and and are themselves similar.
The base case is that objects are maximally similar to themselves
.[4]
It is important to note that SimRank is a general algorithm that determines only the similarity of structural context. SimRank applies to any domain where there are enough relevant relationships between objects to base at least some notion of similarity on relationships. Obviously, similarity of other domain-specific aspects are important as well; these can — and should be combined with relational structural-context similarity for an overall similarity measure. For example, for Web pages SimRank can be combined with traditional textual similarity; the same idea applies to scientific papers or other document corpora. For recommendation systems, there may be built-in known similarities between items (e.g., both computers, both clothing, etc.), as well as similarities between users (e.g., same gender, same spending level). Again, these similarities can be combined with the similarity scores that are computed based on preference patterns, in order to produce an overall similarity measure.
Basic SimRank equation
For a node 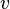 in a directed graph, we denote by
in a directed graph, we denote by  and
and  the set of in-neighbors and out-neighbors of , respectively.
Individual in-neighbors are denoted as
the set of in-neighbors and out-neighbors of , respectively.
Individual in-neighbors are denoted as  , for
, for 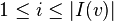 , and individual
out-neighbors are denoted as
, and individual
out-neighbors are denoted as  , for
, for  .
.
Let us denote the similarity between objects and by ![s(a, b) \in [0, 1]](../I/m/95c99a86741d9e961c4b1f938418195b.png) .
Following the earlier motivation, a recursive equation is written for
.
Following the earlier motivation, a recursive equation is written for  .
If
.
If 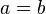 then is defined to be
then is defined to be 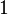 .
Otherwise,
.
Otherwise,

where 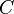 is a constant between
is a constant between  and .
A slight technicality here is that either or may not have any in-neighbors.
Since there is no way to infer any similarity between and in this case, similarity is set to
and .
A slight technicality here is that either or may not have any in-neighbors.
Since there is no way to infer any similarity between and in this case, similarity is set to  , so the summation in the above equation is defined to be when
, so the summation in the above equation is defined to be when  or
or  .
.
Matrix representation of SimRank
Let  be the similarity matrix whose entry
be the similarity matrix whose entry ![[\mathbf{S}]_{a,b}](../I/m/8504d5b9751876519436d79bd1042744.png) denotes the similarity score , and
denotes the similarity score , and 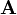 be the column normalized adjacency matrix whose entry
be the column normalized adjacency matrix whose entry ![[\mathbf{A}]_{a,b}=\tfrac{1}{|\mathcal{I}(b)|}](../I/m/3bfbce3d4d3a2152935e37b1ef3c604d.png) if there is an edge from to , and 0 otherwise. Then, in matrix notations, SimRank can be formulated as
if there is an edge from to , and 0 otherwise. Then, in matrix notations, SimRank can be formulated as

where 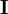 is an identity matrix.
is an identity matrix.
Computing SimRank
A solution to the SimRank equations for a graph 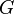 can be reached by iteration to a fixed-point.
Let
can be reached by iteration to a fixed-point.
Let 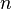 be the number of nodes in .
For each iteration
be the number of nodes in .
For each iteration 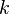 , we can keep
, we can keep 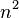 entries
entries  , where
, where 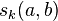 gives the score between and on iteration .
We successively compute
gives the score between and on iteration .
We successively compute 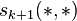 based on .
We start with
based on .
We start with 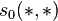 where each
where each  is a lower bound on the actual SimRank score :
is a lower bound on the actual SimRank score :

To compute  from , we use the basic SimRank equation to get:
from , we use the basic SimRank equation to get:

for 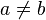 , and
, and  for .
That is, on each iteration
for .
That is, on each iteration  , we update the similarity of
, we update the similarity of  using the similarity scores of the neighbours of from the previous iteration according to the basic SimRank equation.
The values are nondecreasing as increases.
It was shown in [4] that the values converge to limits satisfying the basic SimRank equation, the SimRank scores
using the similarity scores of the neighbours of from the previous iteration according to the basic SimRank equation.
The values are nondecreasing as increases.
It was shown in [4] that the values converge to limits satisfying the basic SimRank equation, the SimRank scores 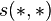 , i.e., for all
, i.e., for all  ,
,  .
.
The original SimRank proposal suggested choosing the decay factor  and a fixed number
and a fixed number  of iterations to perform.
However, the recent research [5] showed that the given values for and
of iterations to perform.
However, the recent research [5] showed that the given values for and 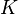 generally imply relatively low accuracy of iteratively computed SimRank scores.
For guaranteeing more accurate computation results, the latter paper suggests either using a smaller decay factor (in particular,
generally imply relatively low accuracy of iteratively computed SimRank scores.
For guaranteeing more accurate computation results, the latter paper suggests either using a smaller decay factor (in particular,  ) or taking more iterations.
) or taking more iterations.
CoSimRank
CoSimRank is a variant of SimRank with the advantage of also having a local formulation, i.e. CoSimRank can be computed for a single node pair.[6] Let be the similarity matrix whose entry denotes the similarity score , and be the column normalized adjacency matrix. Then, in matrix notations, CoSimRank can be formulated as:

where is an identity matrix. To compute the similarity score of only a single node pair, let 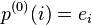 , with
, with 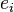 being a vector of the
standard basis, i.e., the
being a vector of the
standard basis, i.e., the 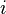 -th entry is 1 and all other entries are 0. Then, CoSimRank can be computed in two steps:
-th entry is 1 and all other entries are 0. Then, CoSimRank can be computed in two steps:


Step one can be seen a simplified version of Personalized PageRank. Step two sums up the vector similarity of each iteration. Both, matrix and local representation, compute the same similarity score. CoSimRank can also be used to compute the similarity of sets of nodes, by modifying  .
.
Further research on SimRank
- Fogaras and Racz [7] suggested speeding up SimRank computation through probabilistic computation using the Monte Carlo method.
- Antonellis et al.[8] extended SimRank equations to take into consideration (i) evidence factor for incident nodes and (ii) link weights.
- Yu et al.[9] further improved SimRank computation via a fine-grained memoization method to share small common parts among different partial sums.
Partial Sums Memoization
Lizorkin et al.[5] proposed three optimization techniques for speeding up the computation of SimRank:
- Essential nodes selection may eliminate the computation of a fraction of node pairs with a-priori zero scores.
- Partial sums memoization can effectively reduce repeated calculations of the similarity among different node pairs by caching part of similarity summations for later reuse.
- A threshold setting on the similarity enables a further reduction in the number of node pairs to be computed.
In particular, the second observation of partial sums memoization plays a paramount role in greatly speeding up the computation of SimRank from  to
to  , where is the number of iterations, is average degree of a graph, and is the number of nodes in a graph. The central idea of partial sums memoization consists of two steps:
, where is the number of iterations, is average degree of a graph, and is the number of nodes in a graph. The central idea of partial sums memoization consists of two steps:
First, the partial sums over  are memoized as
are memoized as

and then is iteratively computed from  as
as

Consequently, the results of ,  ,
can be reused later when we compute the similarities
,
can be reused later when we compute the similarities 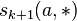 for a given vertex as the first argument.
for a given vertex as the first argument.
See also
Citations
- ↑ I. Antonellis, H. Garcia-Molina and C.-C. Chang. Simrank++: Query Rewriting through Link Analysis of the Click Graph. In VLDB '08: Proceedings of the 34th International Conference on Very Large Data Bases, pages 408--421.
- ↑ W. Yu, X. Lin, W. Zhang, L. Chang, and J. Pei. More is Simpler: Effectively and Efficiently Assessing Node-Pair Similarities Based on Hyperlinks. In VLDB '13: Proceedings of the 39th International Conference on Very Large Data Bases, pages 13--24.
- ↑ H. Chen, and C. L. Giles. "ASCOS++: An Asymmetric Similarity Measure for Weighted Networks to Address the Problem of SimRank." ACM Transactions on Knowledge Discovery from Data (TKDD) 10.2 2015.
- 1 2 G. Jeh and J. Widom. SimRank: A Measure of Structural-Context Similarity. In KDD'02: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 538-543. ACM Press, 2002.
- 1 2 D. Lizorkin, P. Velikhov, M. Grinev and D. Turdakov. Accuracy Estimate and Optimization Techniques for SimRank Computation. In VLDB '08: Proceedings of the 34th International Conference on Very Large Data Bases, pages 422--433.
- ↑ S. Rothe and H. Schütze. CoSimRank: A Flexible & Efficient Graph-Theoretic Similarity Measure. In ACL '14: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1392-1402 .
- ↑ D. Fogaras and B. Racz. Scaling link-based similarity search. In WWW '05: Proceedings of the 14th international conference on World Wide Web, pages 641--650, New York, NY, USA, 2005. ACM.
- ↑ Antonellis, Ioannis, Hector Garcia Molina, and Chi Chao Chang. "Simrank++: query rewriting through link analysis of the click graph." Proceedings of the VLDB Endowment 1.1 (2008): 408-421.
- ↑ W. Yu, X. Lin, W. Zhang. Towards Efficient SimRank Computation on Large Networks. In ICDE '13: Proceedings of the 29th IEEE International Conference on Data Engineering, pages 601--612.