Kaplan–Meier estimator
The Kaplan–Meier estimator,[1][2] also known as the product limit estimator, is a non-parametric statistic used to estimate the survival function from lifetime data. In medical research, it is often used to measure the fraction of patients living for a certain amount of time after treatment. In other fields, Kaplan–Meier estimators may be used to measure the length of time people remain unemployed after a job loss,[3] the time-to-failure of machine parts, or how long fleshy fruits remain on plants before they are removed by frugivores. The estimator is named after Edward L. Kaplan and Paul Meier, who each submitted similar manuscripts to the Journal of the American Statistical Association. The journal editor, John Tukey, convinced them to combine their work into one paper, which has been cited about 34,000 times since its publication.[4]
Basic concepts
A plot of the Kaplan–Meier estimator is a series of declining horizontal steps which, with a large enough sample size, approaches the true survival function for that population. The value of the survival function between successive distinct sampled observations ("clicks") is assumed to be constant.
An important advantage of the Kaplan–Meier curve is that the method can take into account some types of censored data, particularly right-censoring, which occurs if a patient withdraws from a study, is lost to follow-up, or is alive without event occurrence at last follow-up. On the plot, small vertical tick-marks indicate individual patients whose survival times have been right-censored. When no truncation or censoring occurs, the Kaplan–Meier curve is the complement of the empirical distribution function.
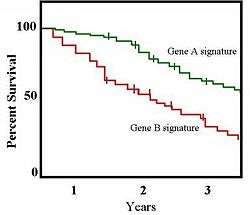
In medical statistics, a typical application might involve grouping patients into categories, for instance, those with Gene A profile and those with Gene B profile. In the graph, patients with Gene B die much more quickly than those with gene A. After two years, about 80% of the Gene A patients survive, but less than half of patients with Gene B.
In order to generate a Kaplan–Meier estimator, at least two pieces of data are required for each patient (or each subject): the status at last observation (event occurrence or right-censored) and the time to event (or time to censoring). If the survival functions between two or more groups are to be compared, then a third piece of data is required: the group assignment of each subject.[5]
Benefits and limitations
The Kaplan–Meier estimator is one of the most frequently used methods of survival analysis. The estimate may be useful to examine recovery rates, the probability of death, and the effectiveness of treatment. It is limited in its ability to estimate survival adjusted for covariates; parametric survival models and the Cox Proportional hazards model may be useful to estimate covariate-adjusted survival.
Example calculation of Kaplan-Meier estimate
The survival function S(t) is the probability that the lifetime of a member of a given population will be greater than the time t. The Kaplan–Meier estimator is a non-parametric estimator of the survival function. Hosmer and Lemeshow [6] describe the Kaplan–Meier estimator as follows. "This estimator incorporates information from all of the observations available, both uncensored and censored, by considering survival to any point in time as a series of steps defined by the observed survival and censored times. It is analogous to considering a toddler who must take five steps to walk from a chair to a table. This journey of five steps must begin with one successful step. The second step can only be taken if the first was successful. The third step can be taken only if the second (and also the first) was successful. Finally, the fifth step is possible only if the previous four were completed successfully. In an analysis of survival time, we estimated the conditional probabilities of "successful steps" and them multiply them together to obtain an estimate of the overall survivorship function."
Collett [7] describes the calculation of the Kaplan–Meier estimate as follows. "To obtain the Kaplan-Meier estimate, a series of time intervals is constructed … Each of these time intervals is designed to be such that one death time is contained in the interval, and this death time is take to occur at the start of the interval. As an illustration, suppose that t(1), t(2), and t(3) are three observed survival times arranged in rank order, so that t(1) < t(2) < t(3) and that c is a censored survival time that falls between t(2), and t(3). The constructed intervals than begin at times t(1), t(2), and t(3), and each interval includes one death time, although there could be more than one individual who dies at any particular time. Notice that no interval begins at the censored time of c. Now suppose that two individuals die at t(1), one dies at t(2), and and three die at t(3). The situation is illustrated diagrammatically in Figure 2.3 [the basis for the figure below], in which D represents a death and C a censored survival time."
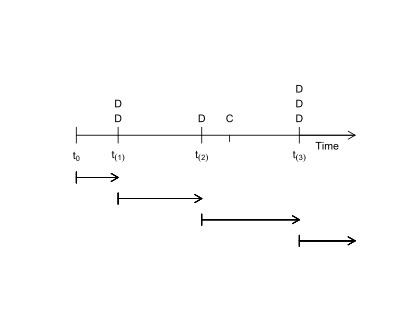
"The time origin is denoted by t0, and so there is an initial period commencing at t0, which ends just before t(1), the time of the first death. This means that the interval from t0 to t(1) will not include a death time. The first constructed interval extends from t1 to just before t2, and since the second death time is at t(2), this interval includes the single death time at t(1). The second interval begins at time t(2), and ends just before t(3), and includes the death time t(2) and the censored time c. There is also a third interval beginning at t(3), which contains the longest survival time, t(3)." [7]
"In general, suppose that there are n individuals with observed survival times t(1), t(2), ..., t(n). Some of these observations may be right censored, and there may also be more than one individual with the same observed survival time. We therefore suppose that there are r death times amongst the individuals, where r ≤ n. After arranging these death times in ascending order, the jth is denoted t(j), for j = 1, 2, …, r, and so the r ordered death times are t(1) < t(2) < t(r). The number of individuals who are alive just before time t(j), including those who are about to die at this time, will be denoted n(j), for j = 1, 2, …, r, and d(j) will denote the number who die at this time…" [7]
"It sometimes happens that there are censored survival times that occur at the same time as one or more deaths, so that a death time and a censored survival time appear to occur simultaneously. In this situation, the censored time is taken to occur immediately after the death time when computing the value of [the number at risk] n(j)." [7]
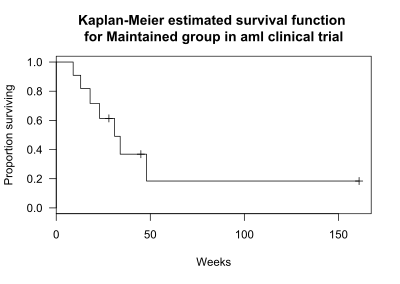
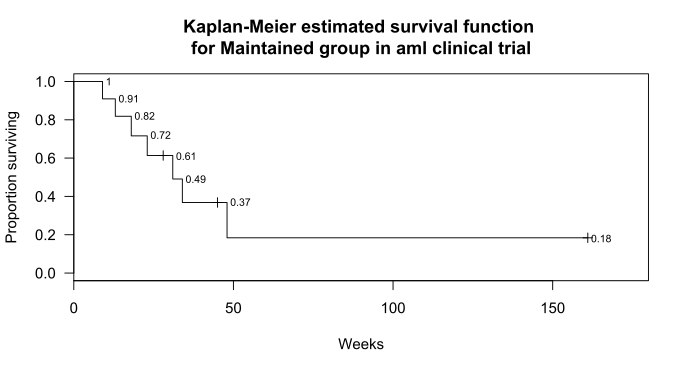
Tableman and Kim [8] give the following example. The data are time to relapse for acute myelogenous leukemia patients in a clinical trial. The data set aml is available in the R package "survival" and from the publisher's website (www.crcpress.com). For this example, only the 11 patients receiving extended treatment ("Maintained") are included. The weeks to relapse for the 11 patients were 9, 13, 13+, 18, 23, 28+, 31, 34, 45+, 48, and 161+ weeks, where the + sign indicates a censored observation. The Kaplan-Meier plot for these subjects is shown in the graph.
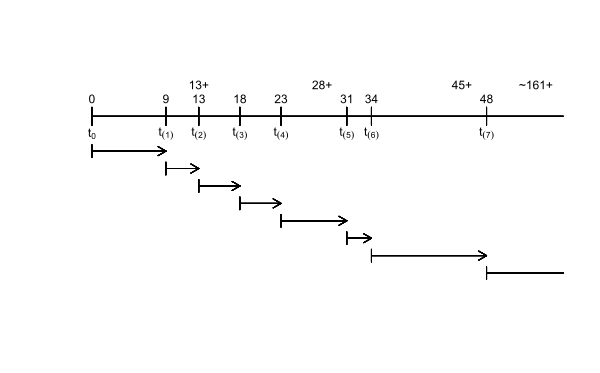
The Kaplan-Meier estimate for the aml data is constructed as follows. For the purpose of this example, the notation t(j) for death times and d(j) for number of deaths should be interpreted as relapse. The figure shows the time origin t0 and the death times t(1), t(2), … , t(7). The death (relapse) times are indicated above the line, as are the times of censoring. The intervals t(1), t(2), … , t(7) are indicated below the line. Notice that each interval begins with a death. The censored observations at 28+, 45+, and 161+ weeks do not mark the beginning of an interval. The censored observation at 13+ weeks occurs at the same time as a death at 13 weeks, which marks the beginning of interval t(2). The number of censored observations in interval t(j) is indicated by c(j).
To calculate the Kaplan-Meier estimate, it is useful to lay out the aml data as shown in a table of ordered time intervals.[9]
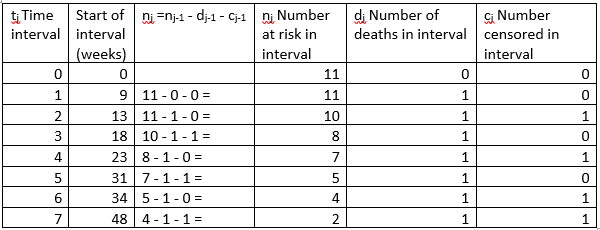
Column 1 in the table gives the ordered death times, t(1) to t(7), plus the time origin, t0.
Column 2 gives the start of t(j) in weeks.
Columns 3 and 4 show the number of subjects at risk at the start of the interval. The number at risk in the interval is n(j) = n(j-1) - d(j-1) - c(j-1), that is, the number at risk in the previous interval, minus losses due to death or censoring.
Column 5 is d(j-1), the number of deaths in the interval.
Column 6 is c(j-1), the number censored in the interval.
Time t0
At the time origin t0, all 11 subjects are alive, and the estimated probability of surviving past t0 is 1.

Time t(1): 9 weeks
Next consider the time t(1) No deaths occur in the interval from t0 to just before t(1). No subjects are censored in the interval from t0 to just before t(1). At time t(1), n(1) = 11 patients are at risk d(1) = 1 patient dies
The probability of surviving past the t(1), given that the subject survived up to t(1), is therefore the proportion of the at-risk subjects who survive:
p(1) = (number at risk – number of deaths)/ (number at risk)
p(1) = (n(1) – d(1))/n(1) = (11 – 1)/11 = 0.91.
p(1) is called a conditional probability: it is conditional on the subject having survived up to t(1). For the aml data, the probability that the subject survived up to t(1) is the probability that they survived past t0, which is :
The Kaplan-Meier estimate of the probability that a subject will survive past time t1 is then

The first death time is at t(1) = 9 weeks. So the probability that a subject will survive past 9 weeks is

Time t(2): 13 weeks
Next consider the time t(2) One death occurs in the interval from t(1) to just before t(2). No subjects are censored in the interval from t(1) to just before t(2). At time t(2), n(2) = 10 patients are at risk d(2) = 1 patient dies
The probability of surviving past the t(2), given that the subject survived up to t(2), is therefore the proportion
p(2) = (number at risk – number of deaths)/ (number at risk)
p(2) = (n(2) – d(2))/n(2) = (10 – 1)/10 = 0.9.
Again, p(2) is a conditional probability: it is conditional on the subject having survived up to t2. For the aml data, the probability that the subject survived up to t2 is the probability that they survived past t1, which was just calculated:

The Kaplan-Meier estimate of the probability that a subject will survive past time t(2) is then

Because , this equation can be re-written as


Further, because , the equation can be simplified to

The second death time is at t_2 = 13 weeks. So the probability that a subject will survive past 13 weeks is

Time t(3): 18 weeks
Next consider time t(3). The calculation for time t(3), at week 18, requires accounting for the one subject who was censored at week 13. That subject is no longer in the risk set at week 18. As shown in the table of ordered time intervals above, the number at risk in the interval t(j) is n(j) = n(j-1) - d(j-1) - c(j-1). For time t(3), this gives n(3) = n(3-1) - d(3-1) - c(3-1). = 10 – 1 – 1 = 8 subjects at risk. Of the original 11 subjects, there are 2 deaths and 1 censored before t3, leaving the 8 at risk.
p(3) = (n(3) – d(3))/n(3) = (8– 1)/8= 0.875.
As before, p(3) is a conditional probability: it is conditional on the subject having survived up to t(3). The probability that the subject survived up to t(3) is the probability that they survived past t(2):

The Kaplan-Meier estimate of the probability that a subject will survive past time t(3) is then

Because , this equation can be re-written as

The third death time is at t(3) = 18 weeks. So the probability that a subject will survive past 18 weeks is

Time t(j): up to 161 weeks
The calculation of the Kaplan-Meier estimates for all the times t0 to t(7) are shown in the table.

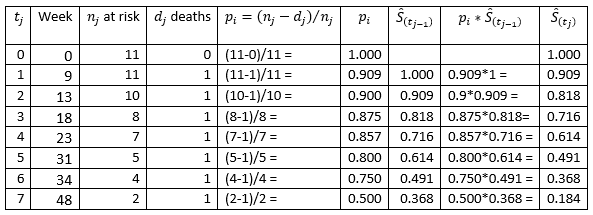
From these examples, it can be seen that the Kaplan-Meier estimate can be calculated as


The table below summarizes the Kaplan-Meier estimates.
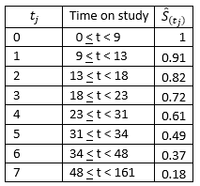
The graph shows the intervals and the Kaplan-Meier estimate of survival for each interval.
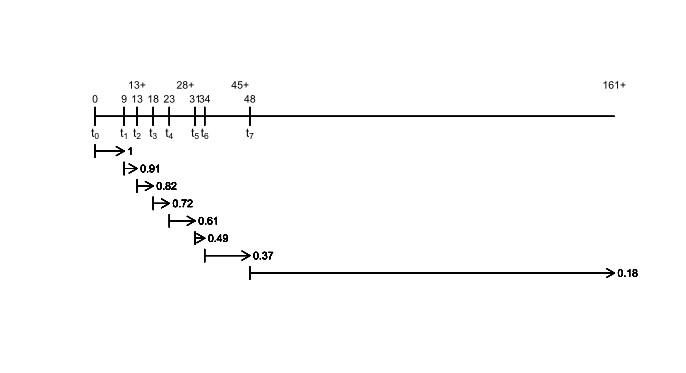
Finally, these estimates are displayed in a Kaplan-Meier plot as shown below, to which the estimate for each interval has been added. Censored subjects are indicated on the graph by a +, visible at weeks 28, 45, and 161.
When there is no censoring, nj is simply the number of survivors just prior to time tj. With censoring, nj is the number of survivors minus the number of losses (censored cases). It is only those surviving cases that are still being observed (have not yet been censored) that are "at risk" of an (observed) death.[10]
There is an alternative definition that is sometimes used, namely

The two definitions differ only at the observed event times. The first definition is right-continuous whereas the alternative definition is left-continuous.
Let T be the random variable that measures the time of failure and let F(t) be its cumulative distribution function. Note that
![S(t) = P[T>t] = 1-P[T \le t] = 1-F(t). \,](../I/m/025e8227464c480f59905f7ee7186911513a06a0.svg)
Consequently, the right-continuous definition of may be preferred in order to make the estimate compatible with a right-continuous estimate of F(t).

Statistical considerations
The Kaplan–Meier estimator is a statistic, and several estimators are used to approximate its variance. One of the most common such estimators is Greenwood's formula:[11]

In some cases, one may wish to compare different Kaplan–Meier curves. This may be done by several methods including:
Other statistics that may be of use with this estimator are the Hall-Wellner band[12] and the equal-precision band.[13]
Implementations in statistics packages
- SAS: The Kaplan–Meier estimator is implemented in the
proc lifetestprocedure.[14] - R: the Kaplan–Meier estimator is available as part of the
survivalpackage.[15][16][17] - Stata: the command
stsreturns the Kaplan–Meier estimator.[18][19] - Python: the
lifelinespackage includes the Kaplan–Meier estimator.[20] - MATLAB: the
ecdffunction with the'function','survivor'arguments can calculate or plot the Kaplan–Meier estimator.[21]
See also
References
- ↑ Kaplan, E. L.; Meier, P. (1958). "Nonparametric estimation from incomplete observations". J. Amer. Statist. Assn. 53 (282): 457–481. doi:10.2307/2281868. JSTOR 2281868.
- ↑ Kaplan, E.L. in a retrospective on the seminal paper in "This week's citation classic". Current Contents 24, 14 (1983). Available from UPenn as PDF.
- ↑ Meyer, Bruce D. (1990). "Unemployment Insurance and Unemployment Spells". Econometrica. 58 (4): 757–782. doi:10.2307/2938349.
- ↑ "Paul Meier, 1924–2011". Chicago Tribune. August 18, 2011.
- ↑ Rich JT, Neely JG, Paniello RC, Voelker CC, Nussenbaum B, Wang EW (2010). "A practical guide to understanding Kaplan–Meier curves.". Otolaryngol Head Neck Surg. 143 (3): 331–6. doi:10.1016/j.otohns.2010.05.007. PMC 3932959
 . PMID 20723767.
. PMID 20723767. - ↑ Hosmer, David; Lemeshow, Stanley (1999), Applied Survival Analysis: Regression Modeling of Time to Event Data (First ed.), Wiley
- 1 2 3 4 Collett, David (2014), Modelling Survival Data in Medical Research (Third ed.), Chapman & Hall/CRC, ISBN 978-1439856789
- ↑ Tableman, Mara; Kim, Jong Sung (2003), Survival Analysis Using S (First ed.), Chapman and Hall/CRC, ISBN 978-1584884088
- ↑ Kleinbaum, David G.; Klein, Mitchel (2012), Survival analysis: A Self-learning text (Third ed.), Springer, ISBN 978-1441966452
- ↑ Costella, John P. (2010). "A simple alternative to Kaplan–Meier for survival curves" (PDF). Unpublished.
- ↑ Greenwood, M. (1926). "The natural duration of cancer". Reports on Public Health and Medical Subjects. London: Her Majesty's Stationery Office. 33: 1–26.
- ↑ Hall WJ and Wellner JA (1980) Confidence bands for a survival curve for censored data. Biometrika 69
- ↑ Nair VN (1984) Confidence bands for survival functions with censored data: A comparative study. Technometrics 26: 265–275
- ↑ The LIFETEST Procedure
- ↑ "survival: Survival Analysis". R Project.
- ↑ Willekens, Frans (2014). "The Survival Package". Multistate Analysis of Life Histories with R. Springer. pp. 135–153. doi:10.1007/978-3-319-08383-4_6. ISBN 978-3-319-08383-4.
- ↑ Chen, Ding-Geng; Peace, Karl E. (2014). Clinical Trial Data Analysis Using R. CRC Press. pp. 99–108.
- ↑ "sts — Generate, graph, list, and test the survivor and cumulative hazard functions" (PDF). Stata Manual.
- ↑ Cleves, Mario (2008). An Introduction to Survival Analysis Using Stata (Second ed.). College Station: Stata Press. pp. 93–107. ISBN 1-59718-041-6.
- ↑ "lifelines"..
- ↑ "Empirical cumulative distribution function - MATLAB ecdf". mathworks.com. Retrieved 2016-06-16.
Further reading
- Aalen, Odd; Borgan, Ornulf; Gjessing, Hakon (2008). Survival and Event History Analysis: A Process Point of View. Springer. pp. 90–104. ISBN 978-0-387-68560-1.
- Greene, William H. (2012). "Nonparametric and Semiparametric Approaches". Econometric Analysis (Seventh ed.). Prentice-Hall. pp. 909–912. ISBN 978-0-273-75356-8.
- Jones, Andrew M.; Rice, Nigel; D'Uva, Teresa Bago; Balia, Silvia (2013). "Duration Data". Applied Health Economics. London: Routledge. pp. 139–181. ISBN 978-0-415-67682-3.
- Singer, Judith B.; Willett, John B. (2003). Applied Longitudinal Data Analysis: Modeling Change and Event Occurrence. New York: Oxford University Press. pp. 483–487. ISBN 0-19-515296-4.
External links
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||